Using Workspaces to Share Data between Jobs
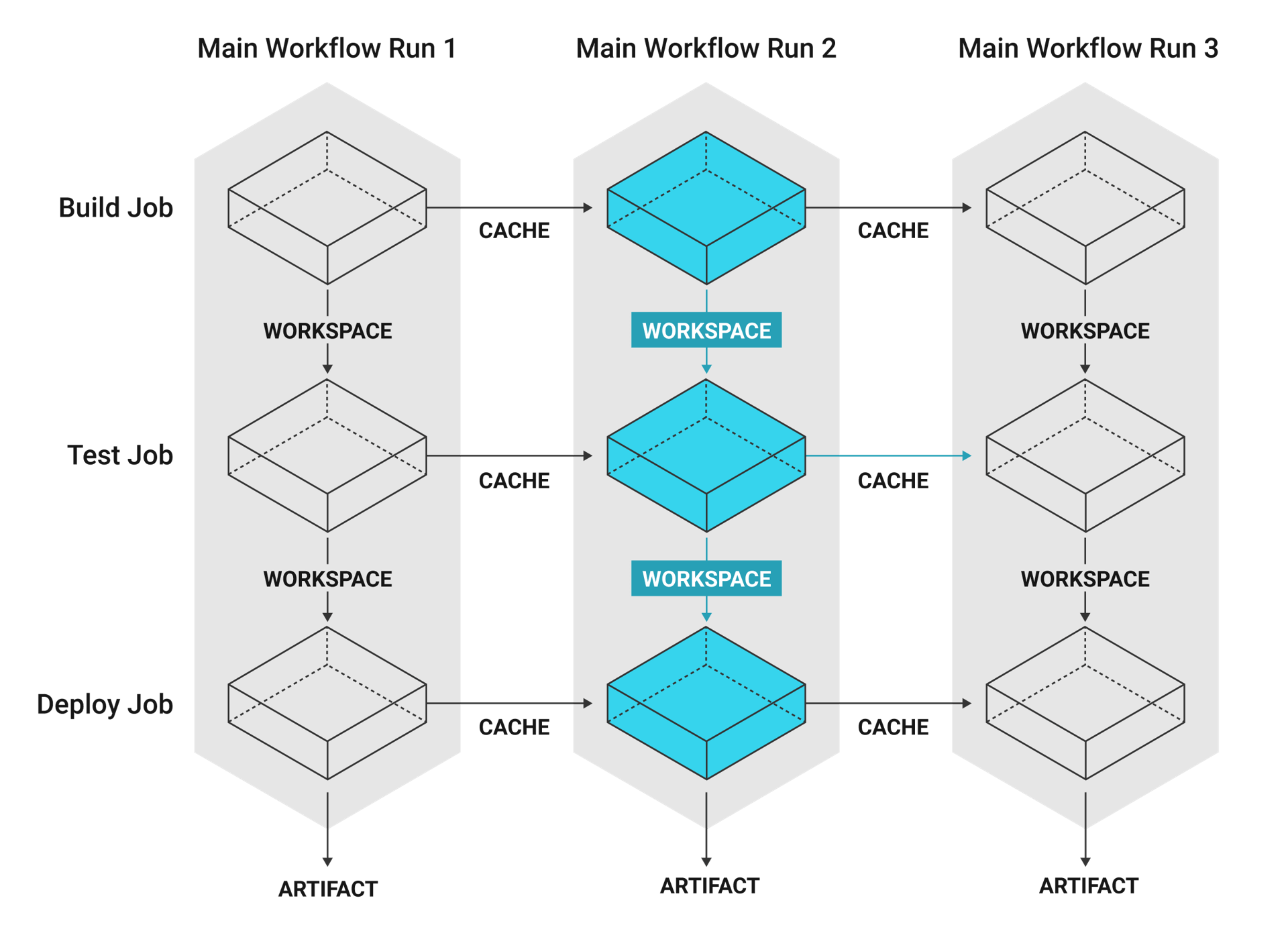
Workflows each have an associated workspace. Workspaces are used to transfer data to downstream jobs as the workflow progresses.
Use workspaces to pass along data that is unique to a workflow and is needed for downstream jobs. Workflows that include jobs running on multiple branches may require data to be shared using workspaces. Workspaces are also useful for projects in which compiled data are used by subsequent test jobs.
For example, a project with a build job that builds a .jar file and saves it to a workspace. The build job fans-out into concurrently running test jobs: integration-test, unit-test, and code-coverage, each of which can have access to the jar by attaching the workspace.
Overview
Workspaces are additive-only data storage. Jobs can persist data to the workspace. When a workspace is used, data is archived and stored in an off-executor store. With each addition to the workspace, a new layer is created in the store. Downstream jobs can then attach the workspace to their execution environment’s filesystem.
Attaching the workspace downloads and unpacks each layer based on the ordering of the upstream jobs in the workflow.
Some notes about workspaces:
-
Each workflow has a temporary workspace associated with it. The workspace can be used to pass along unique data built during a job to other jobs in the same workflow.
-
Jobs can add files into the workspace using the
persist_to_workspacestep and download the workspace content into their file system using theattach_workspacestep. -
The workspace is additive only: jobs may add files to the workspace but cannot delete files from the workspace.
-
Each job can only see content added to the workspace by the jobs that are upstream of it.
-
When attaching a workspace the "layer" from each upstream job is applied in the order the upstream jobs appear in the workflow graph. When two jobs run concurrently, the order in which their layers are applied is undefined.
-
If multiple concurrent jobs persist the same filename, then attaching the workspace will error.
-
If a workflow is re-run, it inherits the same workspace as the original workflow. When re-running failed jobs, only the re-run jobs will see the same workspace content as the jobs in the original workflow.
By default, workspace storage duration is set to 15 days. This can be customized on the CircleCI web app by navigating to . Currently, 15 days is also the maximum storage duration you can set.
Workspace configuration
To persist data from a job and make it available to other jobs, configure the job to use the persist_to_workspace key. Files and directories named in the paths: property of persist_to_workspace will be uploaded to the workflow’s temporary workspace relative to the directory specified with the root key. The files and directories are then uploaded and made available for subsequent jobs (and re-runs of the workflow) to use.
If you have custom storage settings, persist_to_workspace will default to the customizations you have set for your workspaces. If none are set, persist_to_workspace will be the default setting of 15 days.
Configure a job to get saved data by configuring the attach_workspace key. The following .circleci/config.yml file defines two jobs where the downstream job uses the artifact of the flow job. The workflow configuration is sequential, so that downstream requires flow to finish before it can start.
| Using Docker? Authenticating Docker pulls from image registries is recommended when using the Docker execution environment. Authenticated pulls allow access to private Docker images, and may also grant higher rate limits, depending on your registry provider. For further information see Using Docker authenticated pulls. |
version: 2.1
executors:
my-executor:
docker:
- image: buildpack-deps:jessie
working_directory: /tmp
jobs:
flow:
executor: my-executor
steps:
- run: mkdir -p workspace
- run: echo "Hello, world!" > workspace/echo-output
# Persist the specified paths (workspace/echo-output) into the workspace for use in downstream job.
- persist_to_workspace:
# Must be an absolute path, or relative path from working_directory. This is a directory in the execution
# environment which is taken to be the root directory of the workspace.
root: workspace
# Must be relative path from root
paths:
- echo-output
downstream:
executor: my-executor
steps:
- attach_workspace:
# Must be absolute path or relative path from working_directory
at: /tmp/workspace
- run: |
if [[ `cat /tmp/workspace/echo-output` == "Hello, world!" ]]; then
echo "It worked!";
else
echo "Nope!"; exit 1
fi
workflows:
btd:
jobs:
- flow
- downstream:
requires:
- flowFor a live example of using workspaces to pass data between build and deploy jobs, see the .circleci/config.yml that is configured to build the CircleCI documentation.
For additional conceptual information on using workspaces, caching, and artifacts, refer to the Persisting Data in Workflows: When to Use Caching, Artifacts, and Workspaces blog post.
Workspace storage customization
When using self-hosted runners, there is a network and storage usage limit included in your plan. There are certain actions related to workspaces that will accrue network and storage usage. Once your usage exceeds your limit, charges will apply.
Retaining a workspace for a long period of time will have storage cost implications, therefore, it is best to determine why you are retaining workspaces. In most projects, the benefit of retaining a workspace is that you can re-run your build from fail. Once the build passes, the workspace is likely not needed. Setting a low storage retention for workspaces is recommended if this suits your needs.
You can customize storage usage retention periods for workspaces on the CircleCI web app by navigating to . For information on managing network and storage usage, see the Persisting Data page.
Workspace optimization
It is important to define paths and files when using persist_to_workspace. Not doing so can cause a significant increase in storage. Specify paths and files using the following syntax:
- persist_to_workspace:
root: /tmp/dir
paths:
- foo/bar
- bazSee also
-
For conceptual and usage information on Workflows, see the Using Workflows to Orchestrate Jobs page.