The benefits of continuous delivery are well-documented elsewhere. In this post I want to share some of the practices that we use at CircleCI to ensure that our services can safely be deployed continuously.
Our stack is composed of services deployed on Kubernetes. Each service is largely contained in its own git repository and deployed independently of other services. When we deploy a new version of a service, the new code is rolled out pod by pod, by Kubernetes. This means that at any one time, there can be more than one version of the code in production at once.
What follows is a list of practices that we find work well for us as team.
- Prevent Broken Code From Being Deployed
- Know When Code Is Being Deployed
- Ensure Messages Are Delivered
1. Prevent Broken Code From Being Deployed
Some bugs do make it past tests, and are deployed to production. In my experience, one class of bugs that often slips through unit tests are where (well-tested) software components are configured or combined incorrectly right at the top level of the app.
Since we are deploying with Kubernetes, we can use its power to give us an extra safety net when deploying, to help us catch these types of bugs from seeing production traffic.
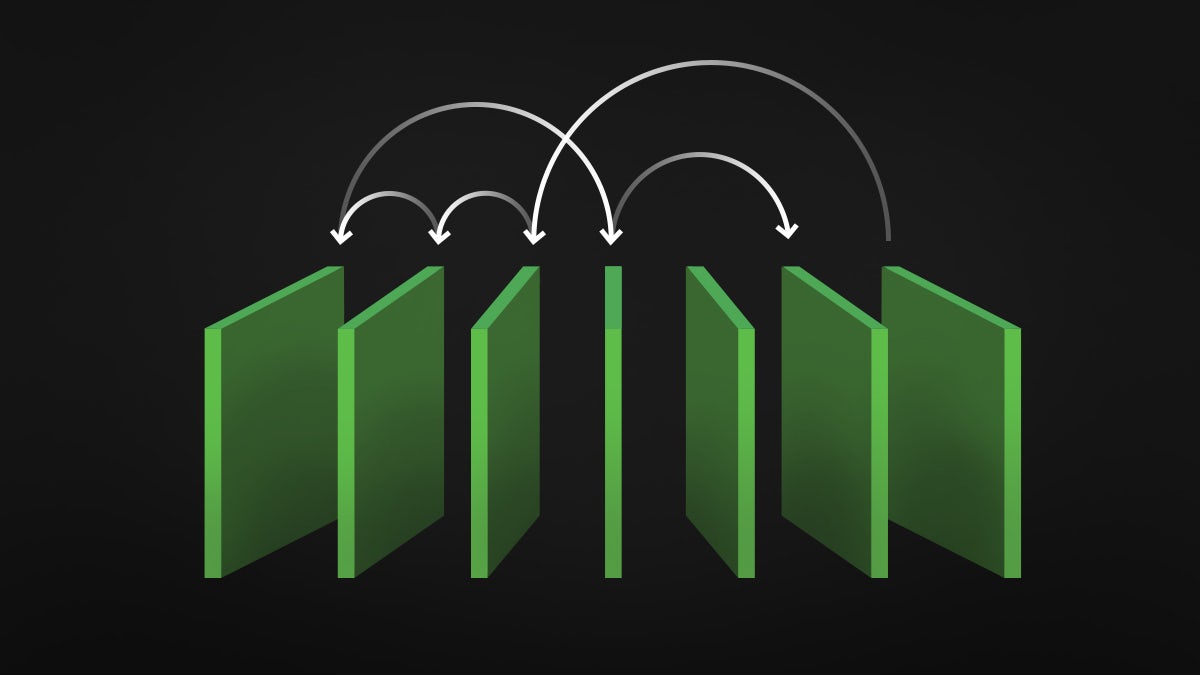
Our Kubernetes setup will usually deploy new pods one-by-one. Consider a service running on 3 pods. When deploying a new release of the service, one pod is started running the new code. Once this pod is healthy, one of the old pods is terminated, and a second new pod is started. Rolling the pods one-by-one like this ensures that we always have 3 healthy pods in production as we deploy code. If a new pod fails to start, Kubernetes will attempt to restart the new pod, over and over, while leaving the remaining 3 pods in place.
We can use this behaviour to our advantage. If we code our services to verify their configuration during initialization, and don’t catch any exceptions, the service will fail to start, and, Kubernetes will prevent that revision of the code from receiving traffic in production.
As an example, let’s say our service has a connection pool for connecting to a redis server. Rather than just configuring the connection pool at startup, we could take a connection from the pool and run a simple statement, such as ECHO "Hello World!", and be sure not to catch any exceptions - just let the service crash if it fails!
Further to this, Kubernetes has 2 types of probes that are used to monitor that status of a pod – the ‘liveness’ and ‘readiness’ probes. The ‘readiness’ probe is used to let Kubernetes know when a service is fully booted and ready to accept incoming requests.
Kubernetes will not route traffic to a pod until the readiness probe is reporting success. This means that the more of our app we can test with a readiness probe, the more Kubernetes can protect us from deploying bugs. I’ve recently written a new service that must be able to communicate with RabbitMQ and AWS S3. By ensuring that the connection to RabbitMQ is connected, and that the service can PUT a file to S3 before return a successful readiness probe, I gain confidence that my service is configured correctly.
2. Know When Code Is Being Deployed
If new versions of services are being deployed throughout the day, we to make our deployments visible to the team. We use CircleCI, Rollbar, and Slack together to make sure we know when code is being deployed.
We use CircleCI to build and deploy our services (of course), and we use Rollbar’s Deploy Tracking API to keep track of deploys (Sentry has a similar feature). We run a script like this on each deploy:
curl https://api.rollbar.com/api/1/deploy/
--form access_token=$ROLLBAR_ACCESS_TOKEN
--form environment=production
--form revision=$CIRCLE_SHA1
--form local_username=$CIRCLE_USERNAME
This gives us two benefits. First, Rollbar is aware of our releases. This reporting, along with our CD practice of deploying smaller changes faster, this means we can easily correlate exceptions reported to Rollbar back to the PR that caused the exception to first occur.
The second benefit is that we can enable Rollbar’s Slack integration, and each team can be notified in Slack each time one of the services that the team owns is deployed.
Here, you can see some Slack traffic where I deployed a new version of a service which contained a bug, immediately followed by the Slack notification of a new class of exception.
Having these alerts in appear in Slack really helps me keep track of who is deploying at any point.
3. Ensure Messages Are Delivered
We use RabbitMQ abundantly at CircleCI for asynchronous communication between services. A typical message would be something like an instruction to run a build of a particular project.
Any service that we run in production might be terminated at any time, and the danger is that a service might consume a message from a message queue, and be shut down before it has a chance to take the required action. This has the same effect as the message being lost. To account for this, we defer acknowledging the receipt of messages until we have performed the required action.
In the case of running a build, this means that we dequeue a message, create a record in a database to represent the build, and then acknowledge receipt of the message. The danger now is that the service might be terminated after creating the record in the database, but before acknowledging the message. If this occurs, RabbitMQ will re-enqueue the message and attempt delivery again, to a different consumer of the queue.
This leads to the scenario that messages can arrive multiple times, and messages can arrive out of order.
In our example, if the message to run a build is re-delivered to a second consumer, a record for that build will already exist in the database. To detect this, we need to include a unique identifier inside each message, maybe a build ID. We can add this build ID to the build record in the database, along with a uniqueness constraint. This constraint then prevents us from being able to create multiple records in the database.
We use the following patterns when consuming from RabbitMQ:
We make sure that all exchanges and queues are declared as durable and we disable auto-delete. We ensure that messages as marked as persistent. We disable auto-acknowledgement of messages in our queue consumers, and instead opt to manually ack or nack messages. We add some a unique ID or idempotency key to messages, so that the consumer can de-dupe messages where required. Passing the responsibility for de-duping messages as far downstream as possible keeps our services as simple as possible.
Conclusion
When designing services, it pays to think upfront about the CD process, and how it will impact your code. Deploy small changes, and deploy as often as possible. Use your deployment tooling to further reduce risk. Be aware of the termination of old pods as well as the deployment of new ones, and take care to make sure your in-flight messages are being delivered reliably.
By making these practices part of your workflow, you are taking steps to make your continuous delivery process as smooth and safe as possible.