
Reliability update 2024-04-18
When we started this series 2 years ago this month, we had just experienced a series of reliability issues. The feedback from you, our customers, was that you wanted to be brought in on what we were doing to remediate the causes of the issues and improve our reliability. We have always valued transparency and sharing our learnings and challenges so others can benefit from them as well, so we started publishing monthly updates right here on our platform reliability work.
After two years reporting our monthly progress, we’re moving away from these updates, but not stopping the work. We’ll continue our commitment to public postmortems for long incidents (you’ll find them here on our status page). It’s scary out there, we know there will be problems in the future, and we’ll communicate any issues that may arise. We’re really proud of the work we’ve done here and from here on out, we’ll shift our communication cadence back to “as needed.”
Over the last two years since we committed to these regular updates, we have made significant improvements to our systems, and this seemed like the right moment to pull them together:
We began by looking at fundamental parts of our platform and identified the primary underlying causes of the problems we were having. We set out to protect the critical path and keep builds running no matter what. We re-architected core systems by re-rebuilding how we handle logs of customer builds. We separated out historical data to protect active pipelines. We invested in VM allocation to better handle cloud provider capacity limits. We improved our incident reporting and in-app statuses to show 3rd party outages as well as those originating on CircleCI, giving customers more insight into their tooling options. We recently increased our synthetic test coverage to better help us quickly identify errors within our systems.
Lastly, we have spent the last year and a half developing integrated deploy and release capabilities into the CircleCI platform. We built these capabilities using internal teams as our first customer and have continued to expand usage across CircleCI. The impact has been real. For example, we recently prevented an incident by identifying and removing a production issue within 4 minutes of release, during which it was only visible to a subset of customers. In many other instances, the progressive deployment tooling identified and automatically rolled back changes that would have had negative customer impact. While we’re delighted with the reliability improvements this tooling has created for CircleCI, we’re even happier to be able to offer it to our customers to help in your own delivery.
Thanks for being on this journey with us and trusting us with your software.
To your continued better building,
Rob + Amit
Reliability update 2024-03-29
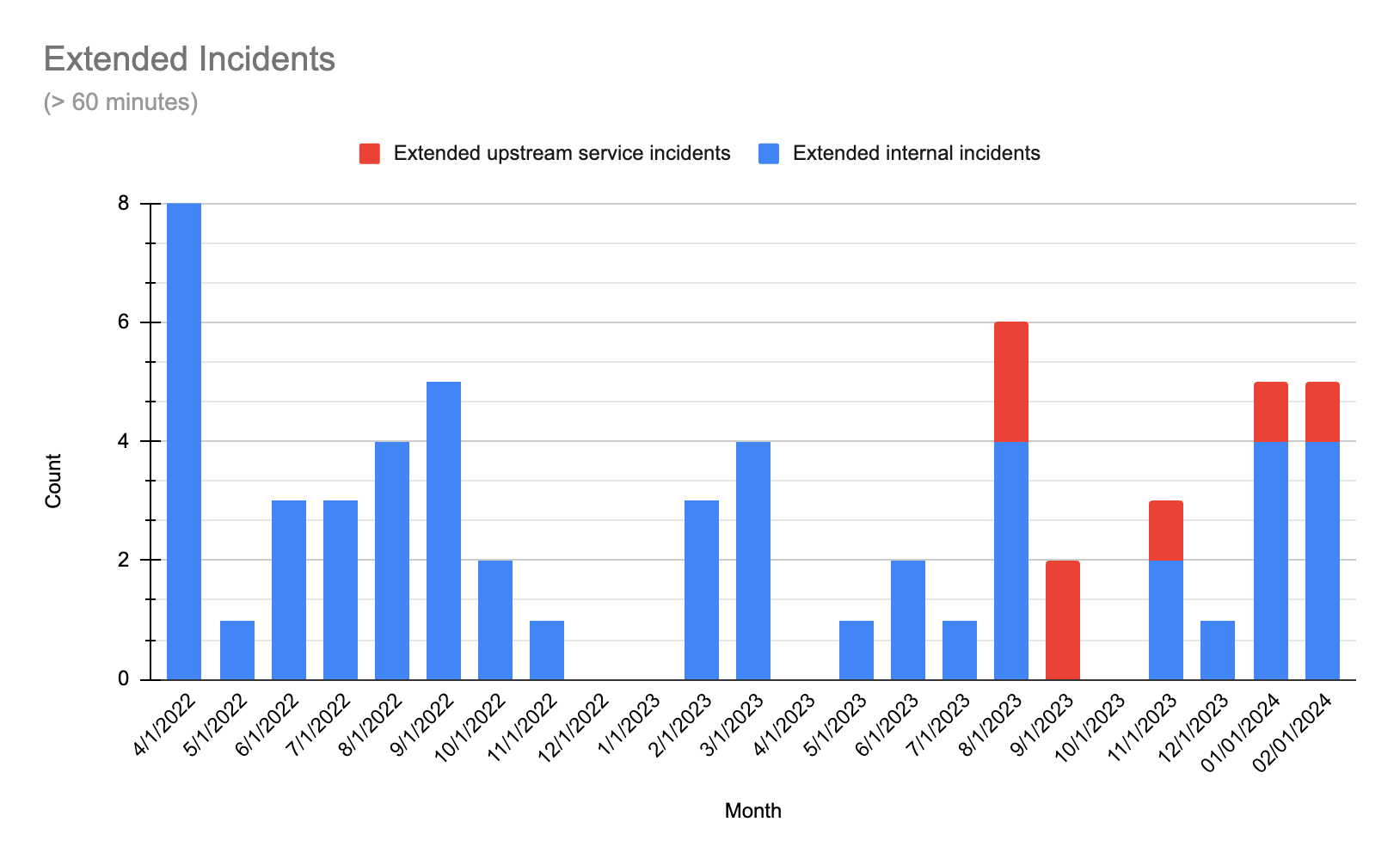
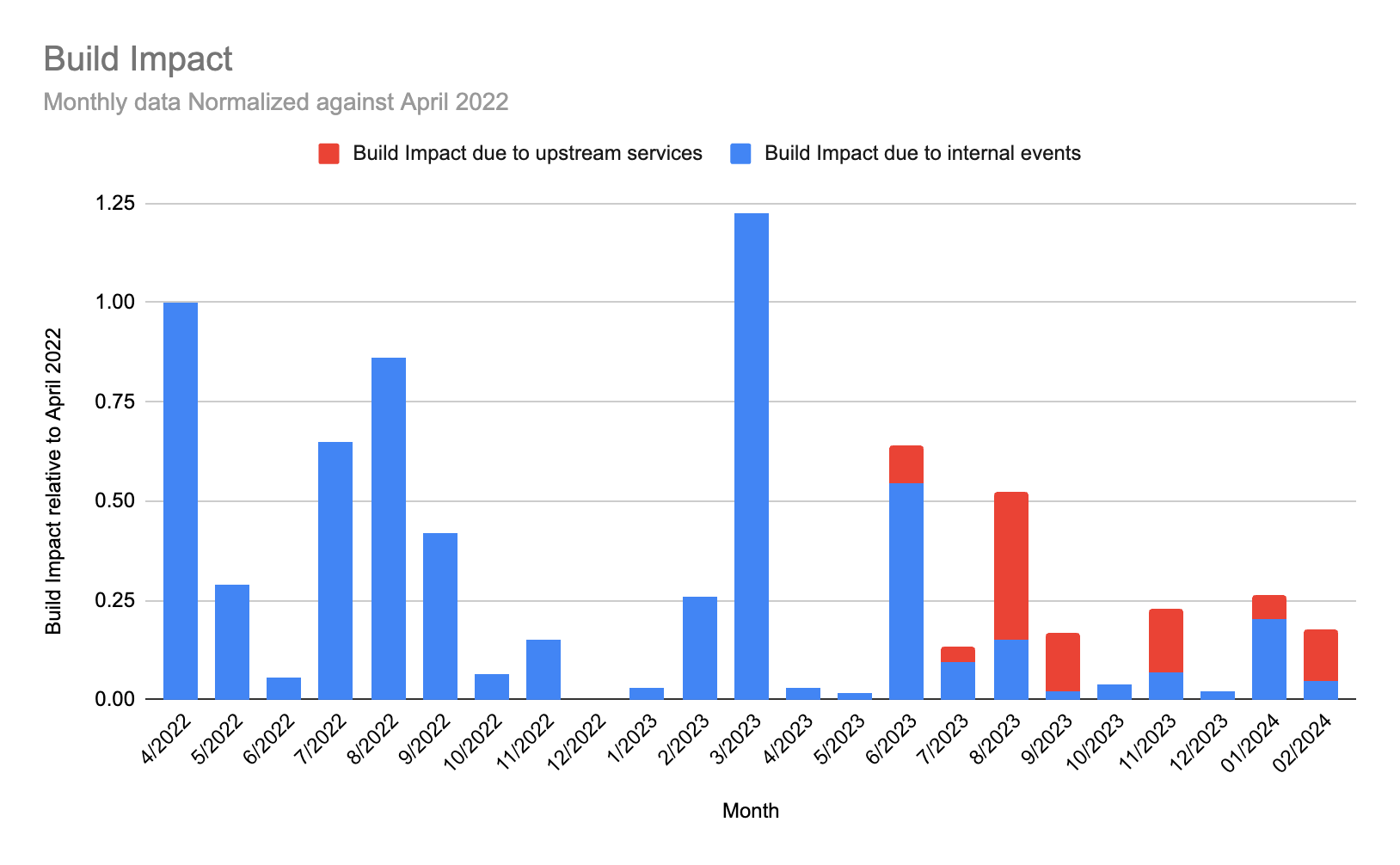
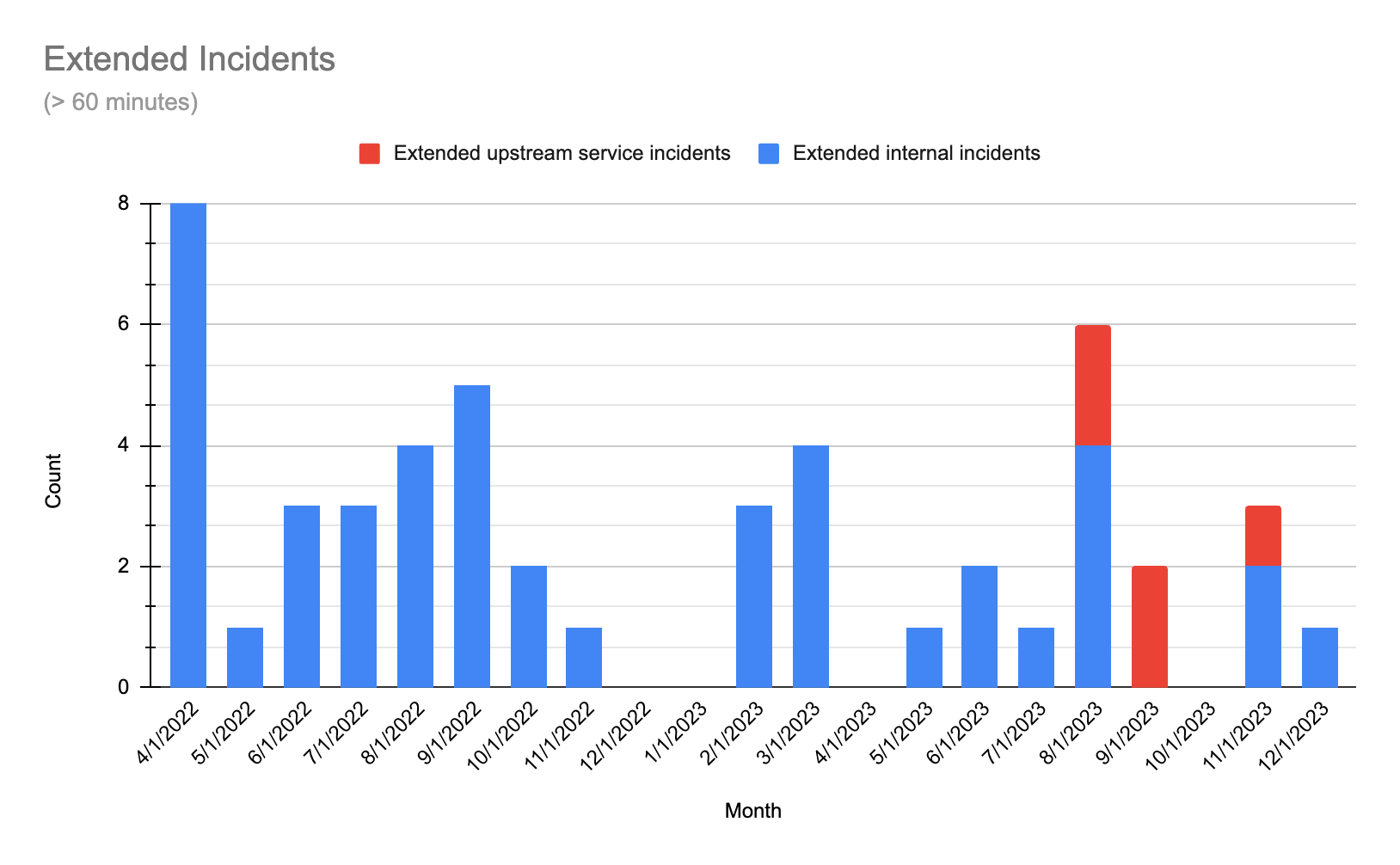
Disruptions to the critical path remained low in February, so we are focusing on reducing the number of extended incidents. Three of the extended incidents in February follow a similar pattern to the incidents we encountered in January, where the errors appeared to fit within expected levels for anticipated failures. The synthetic test coverage outlined in that update has been expanded and we continue to improve it.
The other extended incident had minimal impact on our users despite issues in the infrastructure of one of our third-party providers, reflecting our commitment to safeguarding the critical path.
Reliability update 2024-02-23
We weren’t where we wanted to be in January; we had multiple long incidents. For most of these, the majority of the incident time was spent in detection as a result of elevated error rates that were still within the tolerance of expected error. Therefore, it was not obvious immediately whether the new faults were from our system, or expected error conditions from config files or other customer inputs (for which there is a baseline expected rate).
To prevent this from recurring in the future, we’re increasing the coverage of our synthetic tests. For context, we have a collection of known good pipelines that we execute regularly to validate the correct operation of our core functionality. We’re increasing that coverage to include the kinds of cases we saw in these incidents. Specifically, where differentiating just on error rate would still fall within our error tolerance. When our synthetic pipelines fail, we are certain that the cause is within our own system instead of natural fluctuations in customer errors.
Reliability update 2024-01-18
December was a quiet month for incidents overall. The only issue we recorded was the inadvertent removal of an Xcode image for Intel machines, which was used by a small number of customers. Our monitoring tools alerted us that we had a higher than usual failure rate of Apple build machines and the team went to work restoring the image and syncing it across all the machines in our fleet. The image sync process took longer than usual and contributed to the time it took to restore the availability of the particular missing Xcode version.
This event prompted us to re-evaluate our image-handling review processes, enhance our observability matrix with advanced tools to promptly identify image availability issues, as well as make broad improvements to the image cleanup and distribution process.
Despite the above issue, we maintained our availability goal of 99.9%+ of critical path uptime during December.
We wish you a happy 2024 and look forward to building with you this year!
Reliability update 2023-12-21
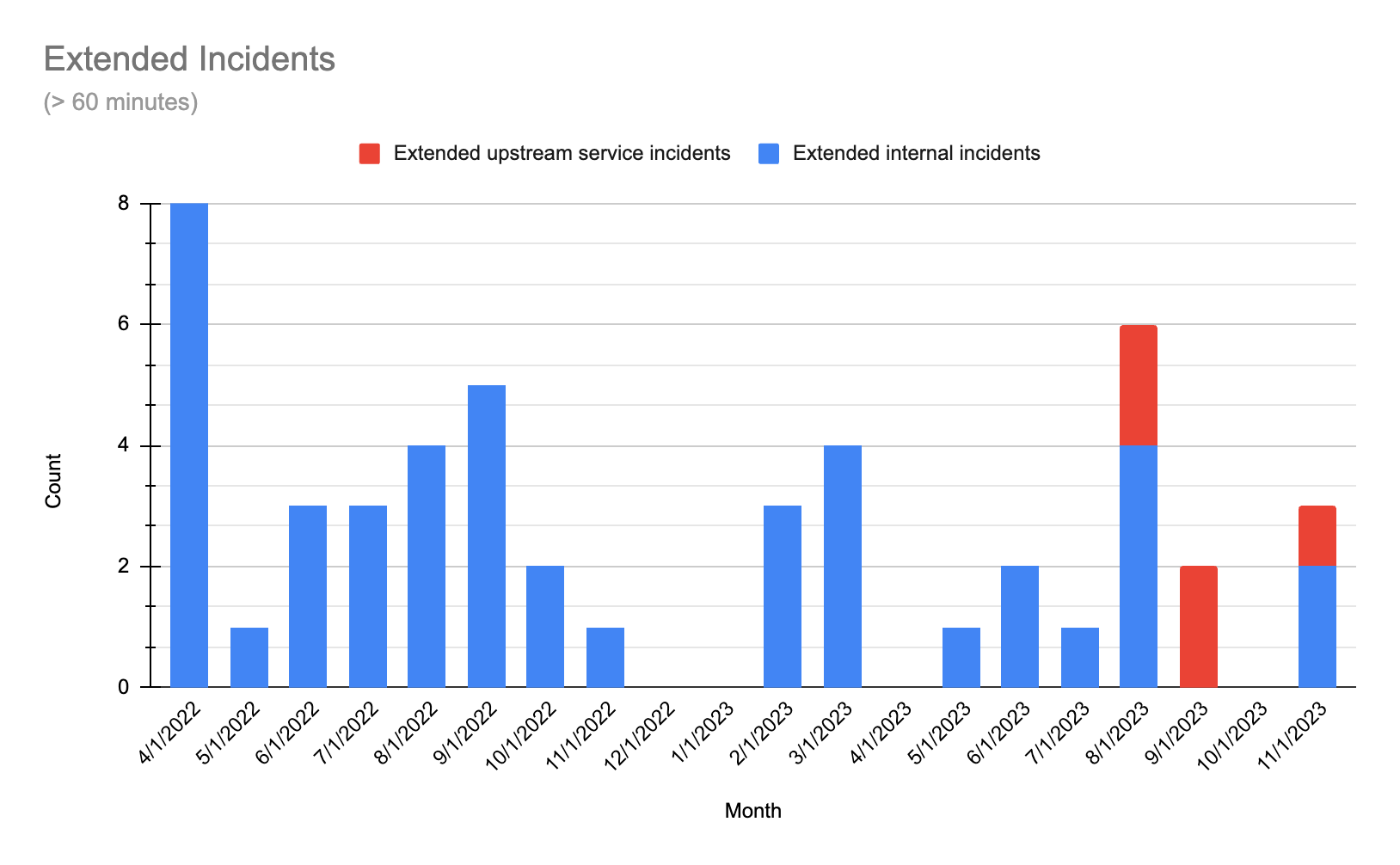
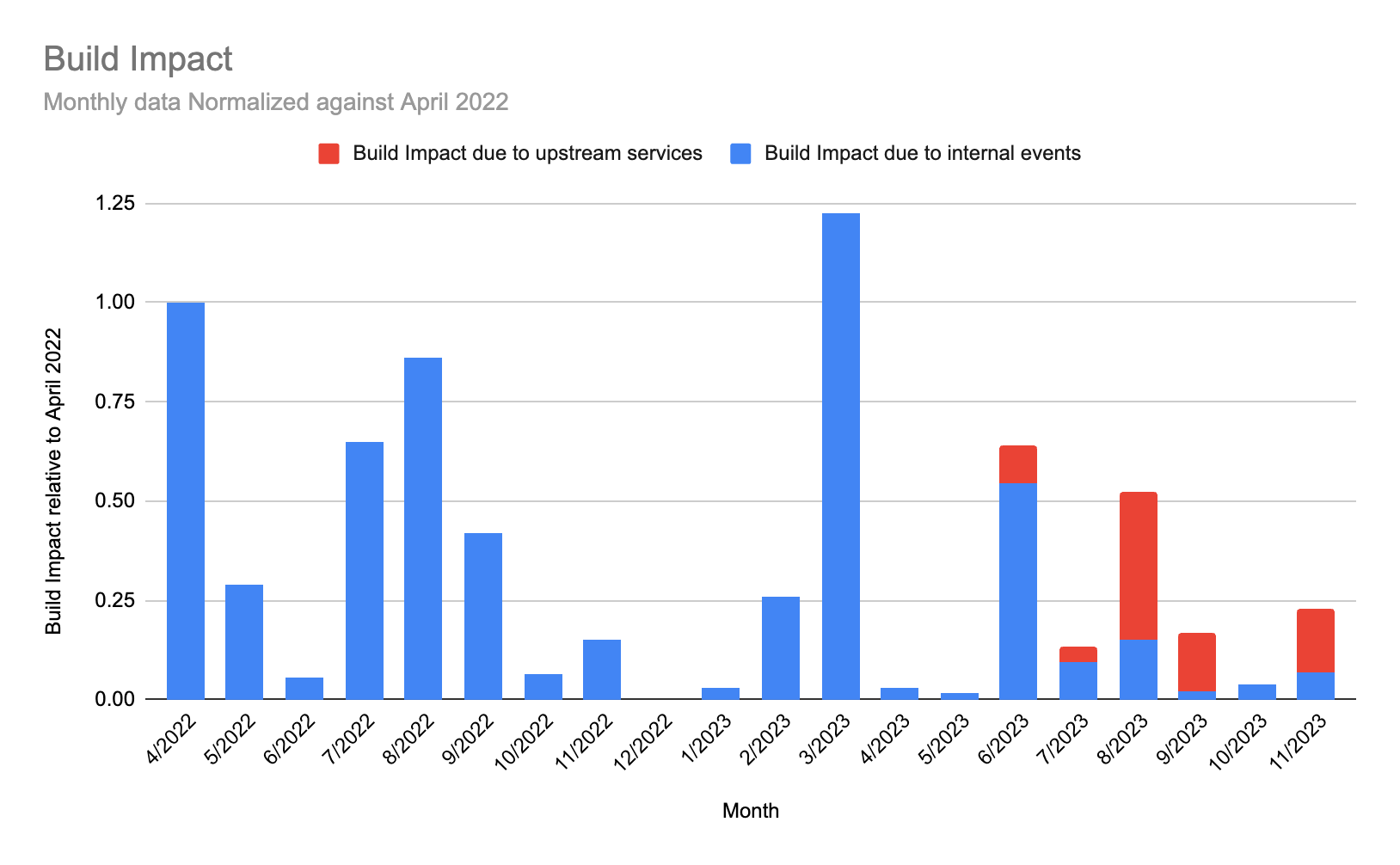
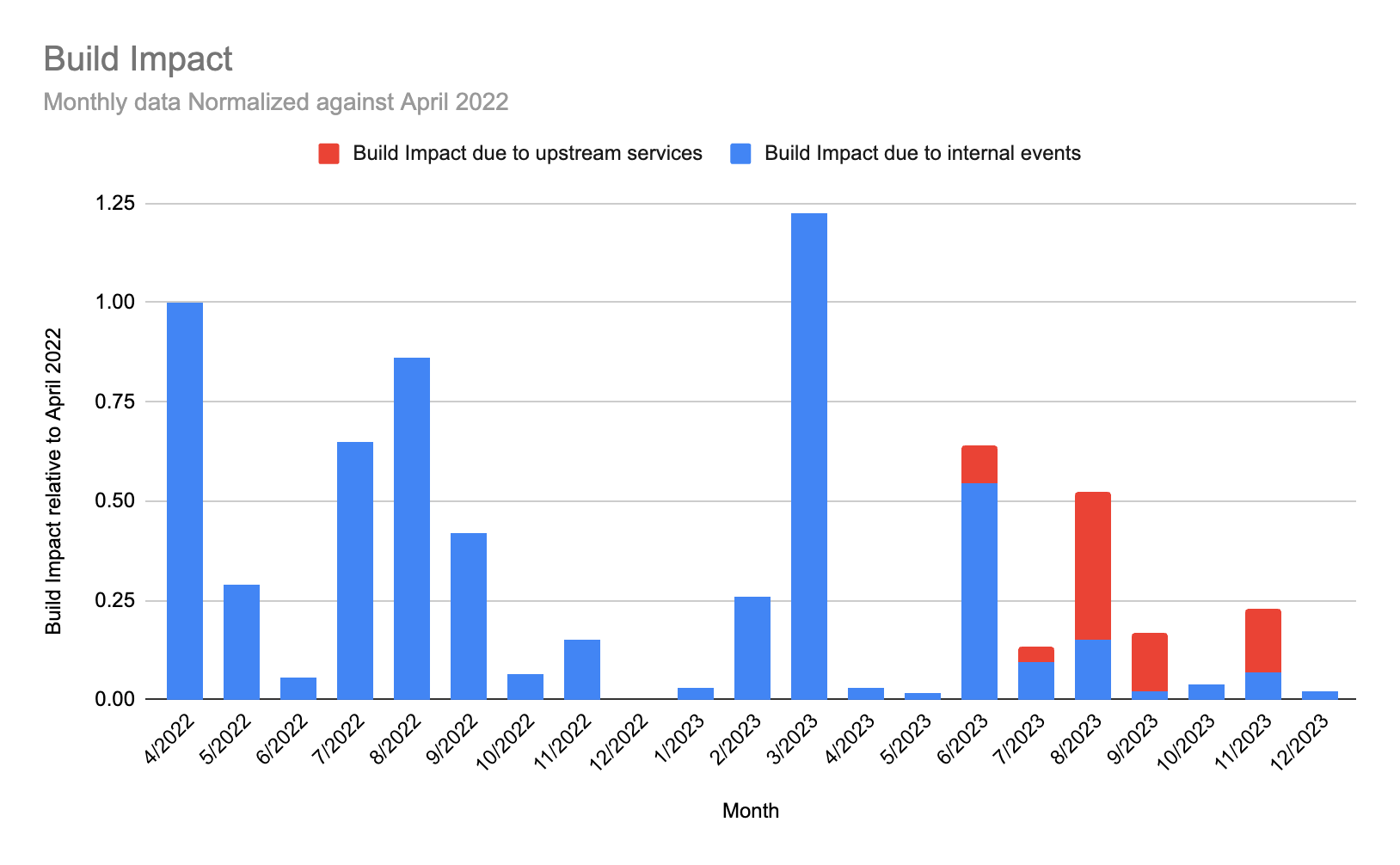
In November, we maintained a high level of reliability (represented by the blue bar on the Build Impact graph). We did experience two extended incidents during November, one of which affected the critical path of running pipelines by impacting GitHub checks, a feature used by about half of our customers as a validation step on PRs. We recognize that while this step is not directly in the pipeline of building and no information was lost, the temporary delays directly impacted delivery flow for our customers. The team immediately identified and fixed issues with monitoring on the impacted service.
System reliability is an ongoing journey, not a destination, and we remain committed to ensuring the critical path–your ability to continue to build no matter what–is as robust as possible. We know how vital the velocity and continuity of the software development life cycle is to any business, and we thank you for trusting us to be a part of yours. From our team to yours, we wish you a safe and happy holiday.
Reliability update 2023-11-17
Summary: The October numbers are in and they continue to trend well. We had very few incidents, and with minimal impact on the customers ability to build.
We continue to invest, because we’ll always be investing in keeping these systems as robust as possible. Systems always evolve and we are ensuring that ours continue to evolve in the direction of simplicity and reliability. It’s always been our aim to share the work we’re doing in case you find yourself in a similar situation.
This month we’ll talk about completing transitions to simplify systems. We’ve talked in the past about isolating the critical path to minimize risk of impact to your builds. However, some things that don’t sound like they’re on the critical path actually are crucial for builds to run smoothly and reliably. In our case, we check your plan to ensure you have access to the requested resources every time you kick off a build.
In order to better align value for our customers, we introduced usage-based pricing in 2018 along with a free tier in place of a timed trial. Like many transitions, we achieved customer functionality (relatively) quickly, however, there was a long tail of customer migration. Only at that point could we begin to remove the historical code paths. During this transition period, the system was in a complex state, with logic spread across disparate services. Often, even after this type of transition is complete, it can be difficult to prioritize simplification against other urgent priorities.
Late last year, as part of our ongoing reliability investments, we identified bursts of high latency in these plan checks as a result of the remaining complexity; as of September, we removed all the remaining legacy code paths, greatly streamlining the system and reducing the number of internal errors by 99%.
Reliability update 2023-10-13
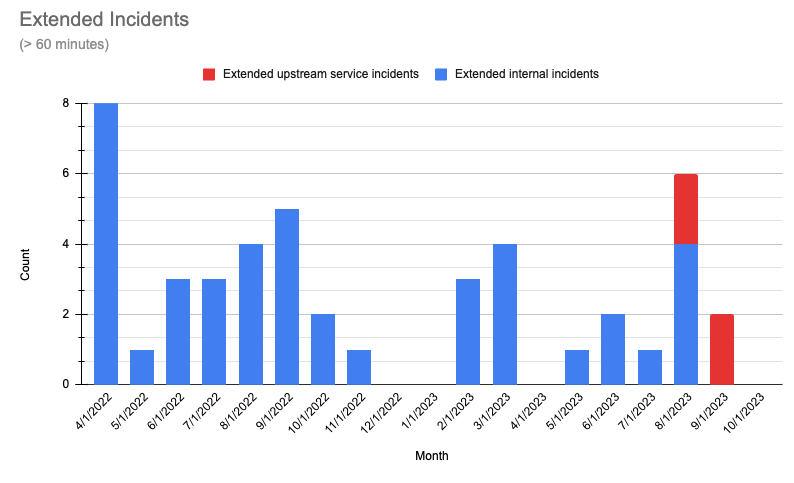
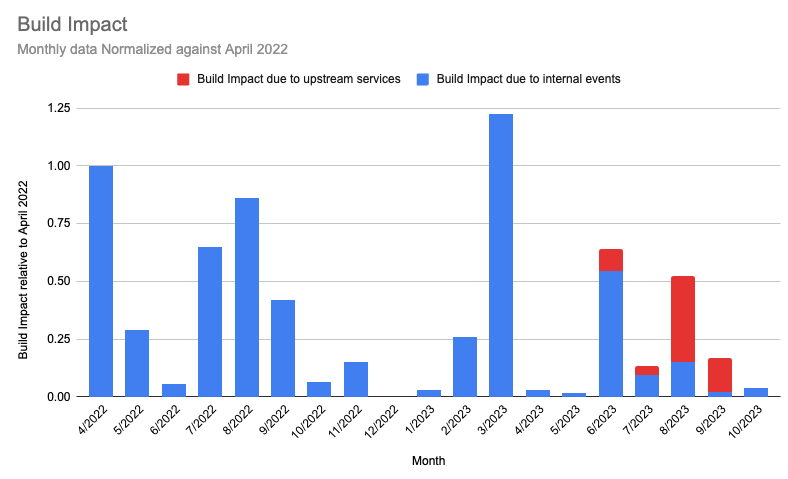
Summary: In September, we experienced two 60+ minute incidents, both as results of outages by upstream providers. Any additional build impact on customers beyond these two upstream incidents was minimal.
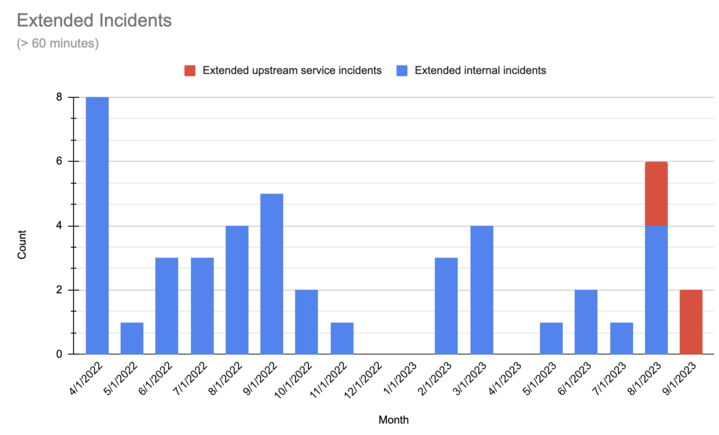
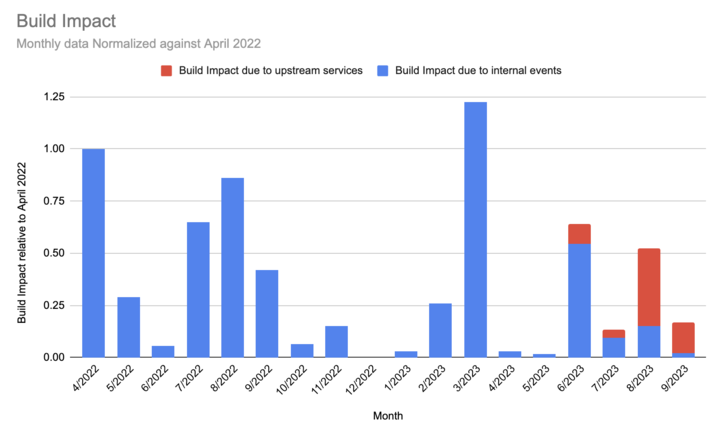
Note: We’ve begun separating the data by outage source: red bars indicate outages caused by upstream providers; blue represent issues originating within our platform. Our delineation of sources begins in June 2023.
This month, we also want to give an update on something we discussed in our July update referring to an incident from 2023-06-15. The work in progress we described at that time (replacing a service) is now complete, and has been a huge win for us as a team, as well as for our reliability. What follows is the results and what we learned from the process.
Like so many problems in software, this is a story of complexity. I often advise using the simplest solution until it can no longer meet your needs, and this is a great example of why. We had built an overly complex system in anticipation of need. In the end, simplifying it not only made it easier to reason about but it also improved performance and reduced resource overhead.
For the curious, here are the details:
When you run a pipeline, the step in an individual job needs to be piped into storage and back to you in the browser, which would previously open up a sustained gRPC connection for the duration of each job’s execution. This process was managed by our output processor (OP) service , which was resource-intensive, and overloaded with multiple responsibilities.
In order to stream output, the OP relied on several sustained gRPC connections. As a result, an OP instance crash was prone to losing step output and possibly even job state. Additionally, these long-lived gRPC connections reduced the effectiveness of load-balancing.
To overcome these issues, we introduced step service. Its creation was geared specifically towards addressing the deficiencies of the OP, focusing on singular responsibility, enhancements in stability, and fault tolerance. This ultimately resulted in higher performance for our customers. Writing something optimized for simplicity and performance also resulted in 90+% fewer compute resources, as compared to OP.
While it’s highly likely that we could have invested in tuning gRPC to meet our needs, we have a lot of experience with REST protocols, so the step service is well-suited to the team today, and therefore, easier to manage. With that mental overhead reduced, we can now invest our energy in other things. Everything is an opportunity cost. We know our great opportunity is not in fine-tuning a protocol we didn’t need to begin with.
By picking our worst offender in resource consumption, we were able to focus our energy on fixing the problem and create a better solution; now with that checked off, the team is free to tackle the next biggest obstacle to reliability, stability, and performance.
Reliability update 2023-09-29
This month, we’re focused on sharing a more comprehensive picture of our reliability and availability.
We experienced 6 extended incidents, 2 of which were due to an upstream third party. While we always want to be transparent with our performance against our stated goals, it’s crucial to note that, while they lasted 60 minutes or longer, the impact of these August incidents on our business operations was relatively minimal. These instances were largely restricted to rare edge cases, making them particularly challenging to anticipate and, as such, they aren’t necessarily representative of our standard performance.
Despite the number of extended incidents, our overall service availability continues to maintain desired levels, demonstrating our commitment to protecting the critical path.
Navigating third-party outages to reduce build impact
As mentioned above, 2 of our extended incidents during August were actually the result of incidents on GitHub. Like you, we rely on third party systems to keep CircleCI up and running.
And while we continue to be ruthlessly focused on reducing the amount of time where you are unable to build, we’ve seen an emerging theme over the last 3 months: more frequent outages occurring on the third parties you, and we, rely on.
Better information leads to faster recovery
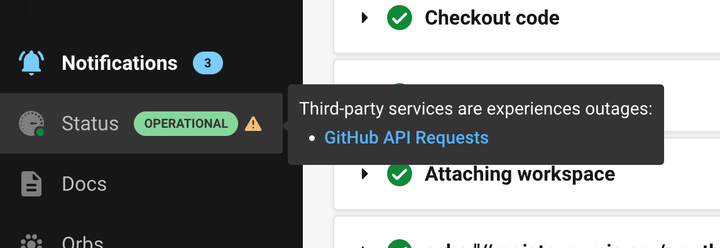
While we’ve been able to recover from these incidents quickly, in these moments of incidents and outages, we’re all customers who wish we had better information to make decisions that lead to triage and recovery. To that end, we now have improved in-app notifications on CircleCI and clearly indicate what’s impacting your ability to build (see below). These in-app notifications will give you more information to make choices that keep you building.
Benchmarking our reliability progress
If you scroll down this blog post to the beginning of our renewed reliability promise to you, you’ll see that we’ve centered a lot of our work on making key changes to become the most reliable CI/CD platform on the market. Our goal is to build the most stable, future-proof CI/CD platform in the market. And, while it’s important for us to evolve, we’re equally committed and relentlessly focused on staying ahead of our competitors when it comes to reliability.
Over the last year, we’ve been so focused inwardly on improving our own systems that we wanted to take the opportunity to benchmark ourselves against our peers in terms of reliability. And while we’re not declaring “mission accomplished” by any means, the signs and signals are encouraging.
Reliability is an industry-wide challenge. As an example, GitHub Actions has suffered 85+ hours of degraded performance so far this year, compared to CircleCI’s 20 hours – over 4x worse performance. Other CI/CD vendors that may offer CI/CD as an add-on to their core product do not have our same all-out focus on protecting your work, or product capability to ensure reliable performance at scale. And while no degradation of performance is acceptable, it shows that our commitment to keeping you building by protecting the critical path is working.
We’ve been transparent about our struggles, and while we will continue to strive for better uptime, fewer incidents, and less impact to your projects, the time felt right to put our strong reliability performance in industry context.
Cheers to continuous improvement and better building.
Reliability update 2023-08-23
Overall, the July numbers reflect continued progress in the right direction. The number of incidents, the number of incidents over 60 minutes, and the overall build impact are all down month-over-month. Ultimately, this outcome is good for you, our customer. While we will continue to focus on the impact of incidents, we’re now expanding our focus in a new phase of this journey.
The numbers that we have been reporting so far are primarily oriented around availability or uptime. Those are important because when we have major service degradations, our customers are impacted. That said, availability numbers aren’t the full picture. Large systems are usually not “up” or “down,” but rather fluctuate in their performance. We are digging deeper into the areas in between incidents to ensure all of our customers are having great experiences and ultimately looking to share that view as part of this series. We’ll share more details on those learning in next month’s update.
As we continue to improve, we will continue to set the bar higher. Because ultimately, every build matters.
Reliability update 2023-07-14
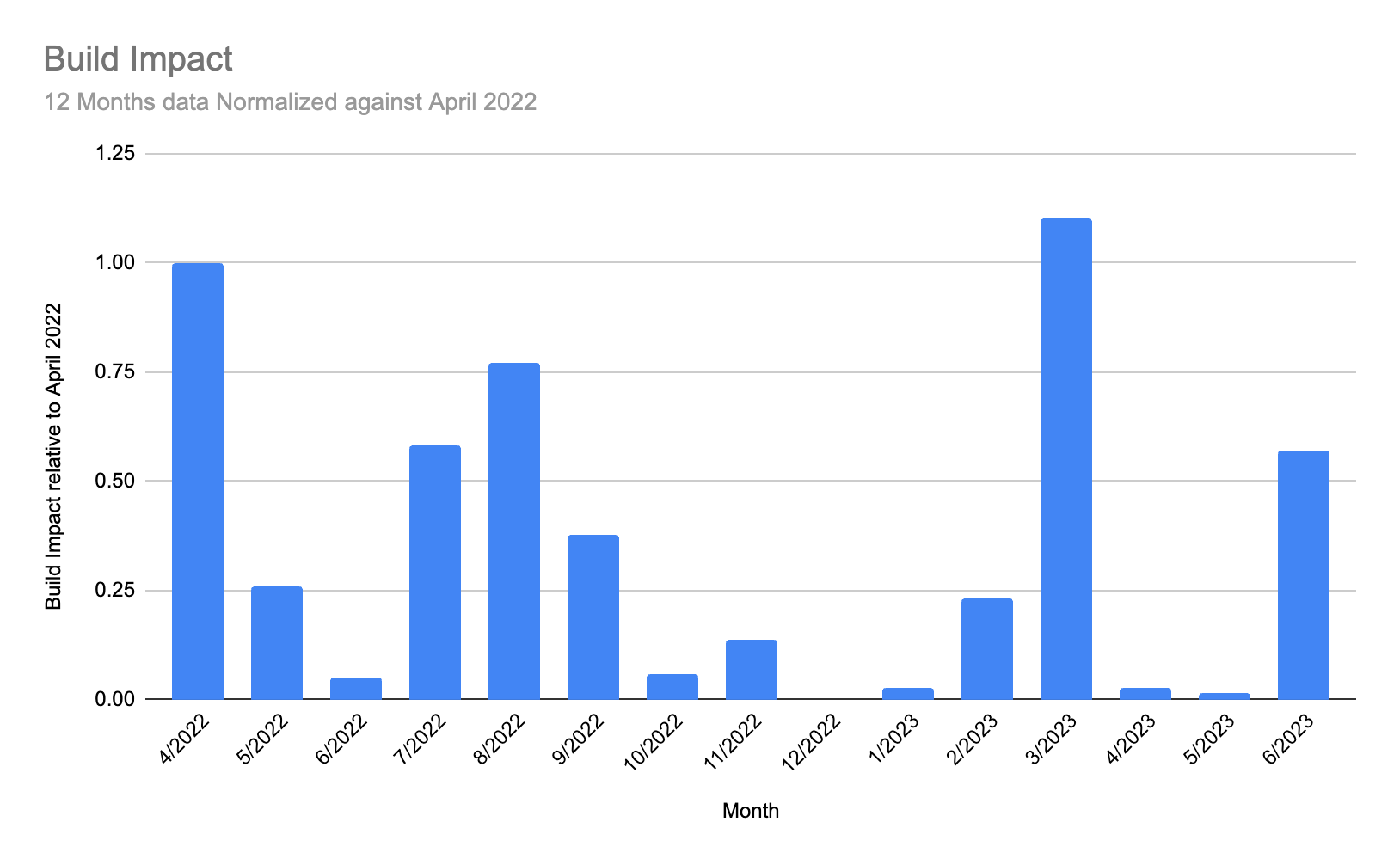
The Build Impact number for June is higher than we’re aiming for. There were two significant incidents that drove this number. Here is more context:
- A 2023-06-15 incident impacted all customers and was tied to a service that we have been actively working to replace. While we had started the process of moving to a more robust system, we hit a capacity limit on underlying data storage much earlier than expected. Since the incident, we have upgraded infrastructure components to keep up with demand as we execute the migration.
Completing the replacement of the service in question will mark the end of a series of upgrades to our core job execution engine that has already had significant impacts for the stability of that area.
- A 2023-06-29 GitHub incident impacted the majority of our customers. While we rely on 3rd-party systems and are impacted when they are down, we were able to recover as soon as they were back online, which was a result of multiple investments in handling these significant demand surges.
The ongoing work to manage 3rd party systems and decommissioning services that don’t meet our needs will continue. But as I’ve referenced here, we’ve made some longer term investments and they are showing dividends. When discussing reliability, we don’t often talk about the problems we avoided as a result of our investments. Here are a few examples that show how when we were faced with potential disruptions later down the line, we were ready, and successfully prevented customer impact.
- After an incident we had last summer (June 2022), which was a series of API abuse attacks that had downstream impacts on our platform, we made significant investments across multiple layers of our API serving infrastructure. This return on investment was realized in February 2023, when we suffered similar abuse attempts but at 4x the scale. No engineering intervention was required and no customers were impacted.
- After an incident we had late last year (September 2022), which was a multi-hour disruption due to AWS capacity issues, we implemented a fallback approach for VM allocation that adapts to AWS instance availability. Building on top of earlier investments in more robust VM management, we have avoided similar large impacts as well as reducing VM wait time during daily fluctuations in AWS capacity.
- Protecting your ability to build is our primary goal and the separation of the critical path has been our focus. A multi-hour outage (September 2022) was triggered by a confluence of factors impacting the postgres cluster for one of our core services. Immediately afterward, we began investing in separating out historical data to protect active pipelines, starting with that service. We witnessed the same confluence of factors earlier this year and the issue was resolved in under 10 minutes and with no customer impact.
While these wins are exciting because they make our platform more reliable, we know any disruption that prevents you from building is far from ideal. We’re continuing to stay the course, and with these investments in these key areas, we’re confident we’re on the right path.
Reliability update 2023-05-31
We’re continuing to see the results that we’re aiming for, and the longer incidents impacting your build time are fewer and farther between. Today, we’ll briefly share what we’re doing and how we’re measuring success.
We’re continuing to report on the same numbers. See the previous update below for background.
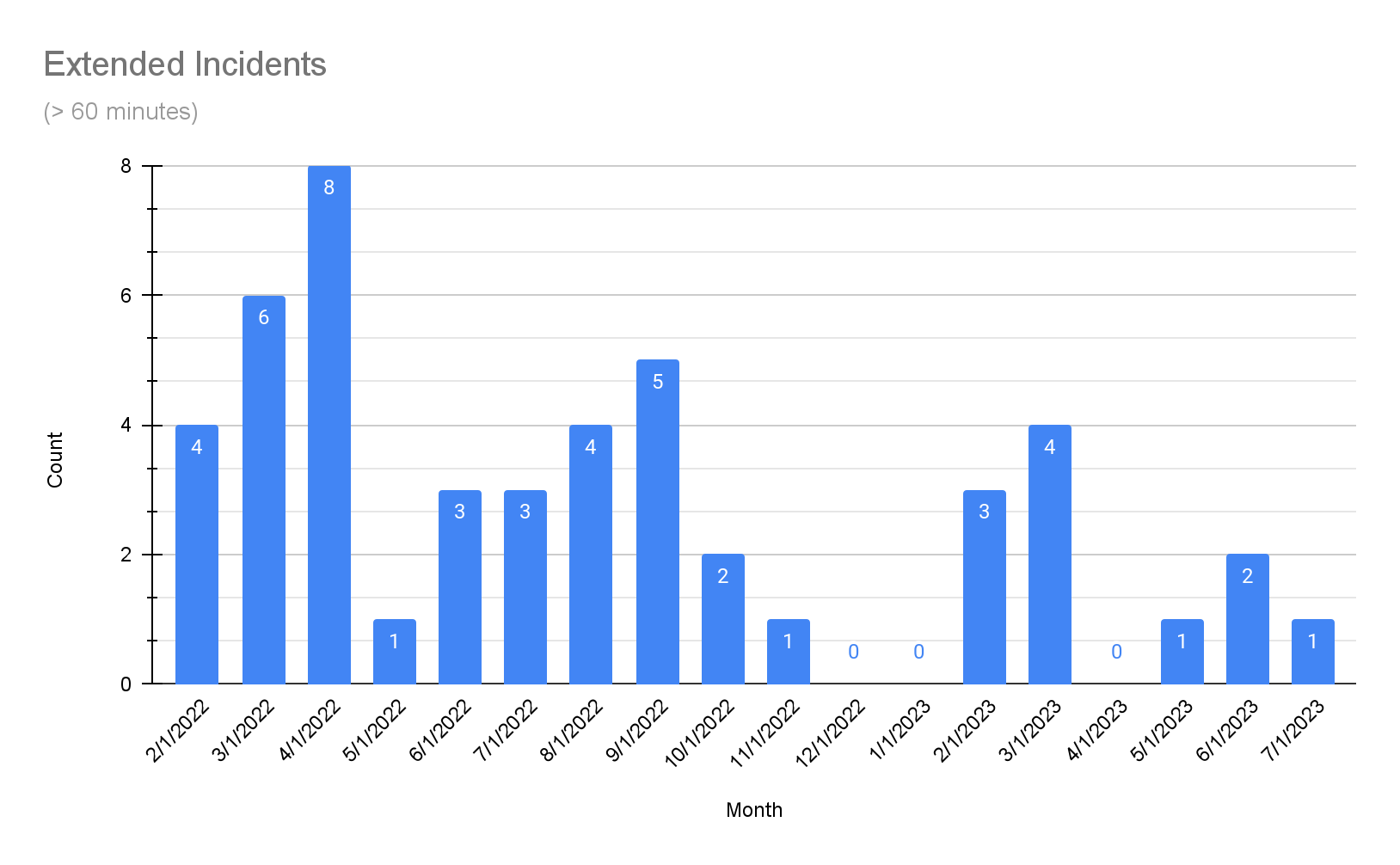
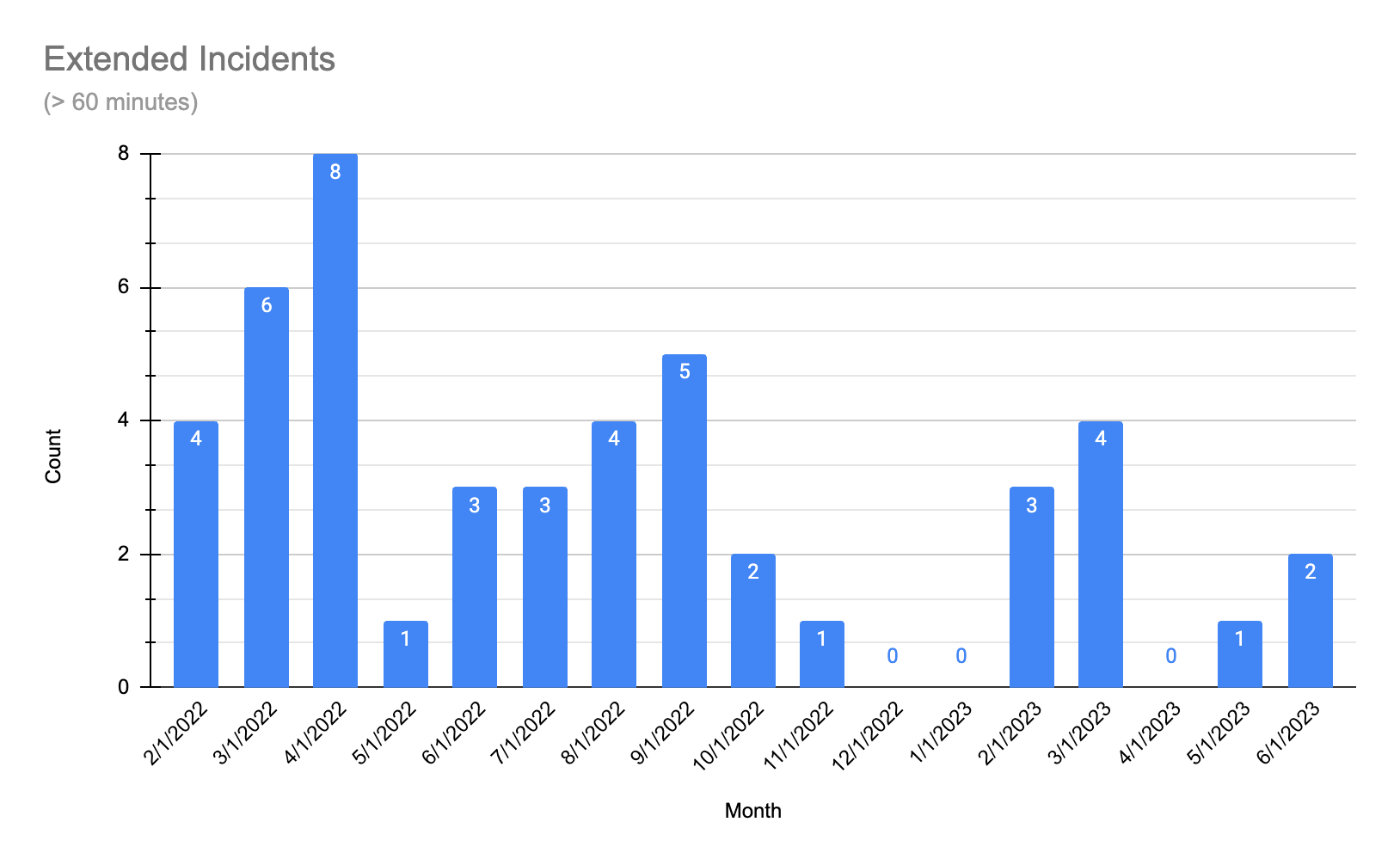
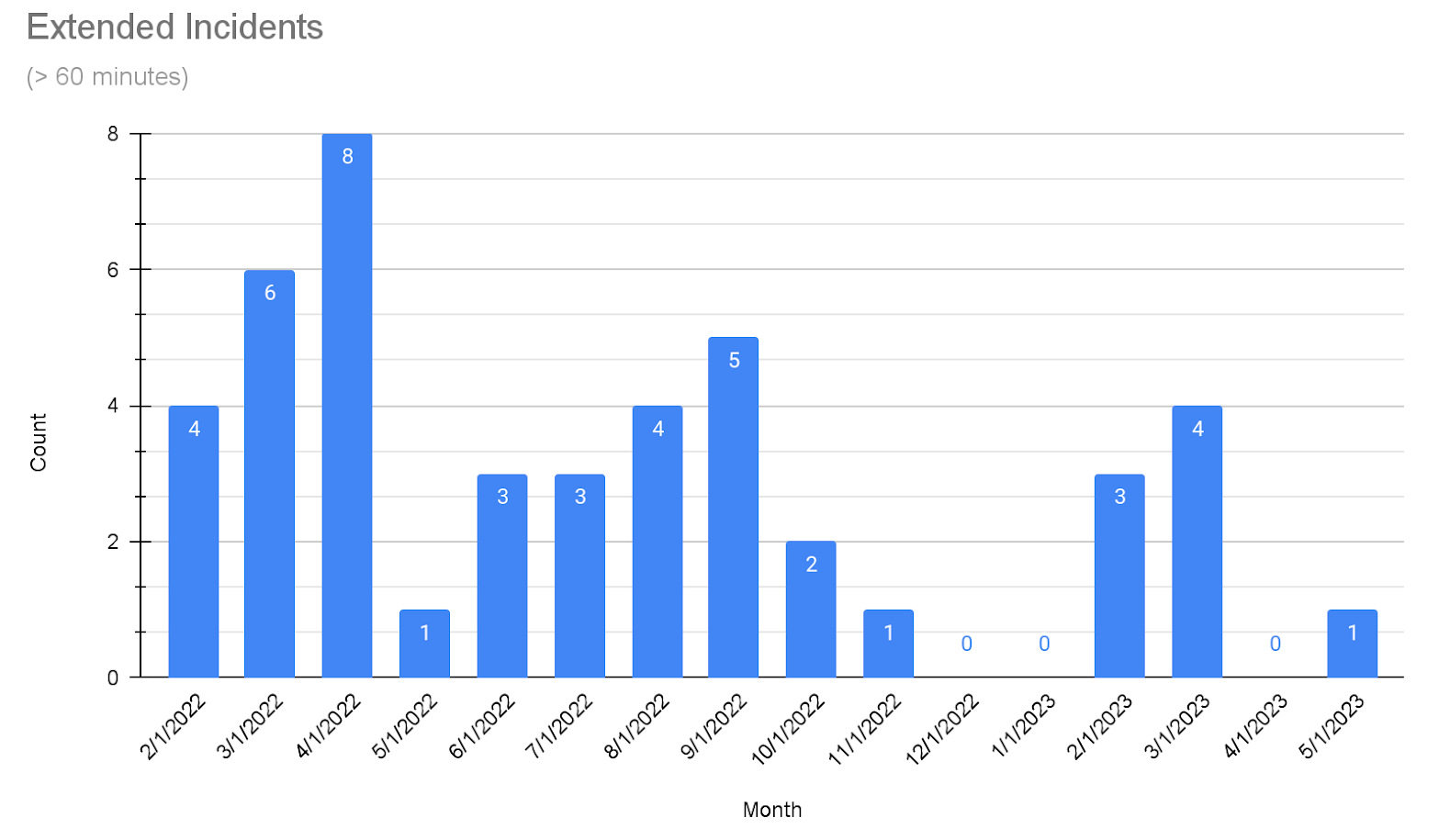
Extended incidents
One metric we are focused on is the number of extended incidents. We’re defining extended incidents as incidents lasting over 60 minutes, and focusing there because when we have short incidents, we can generally get you back to work quickly. We’re always working to do better, but we’re happy with this outcome.
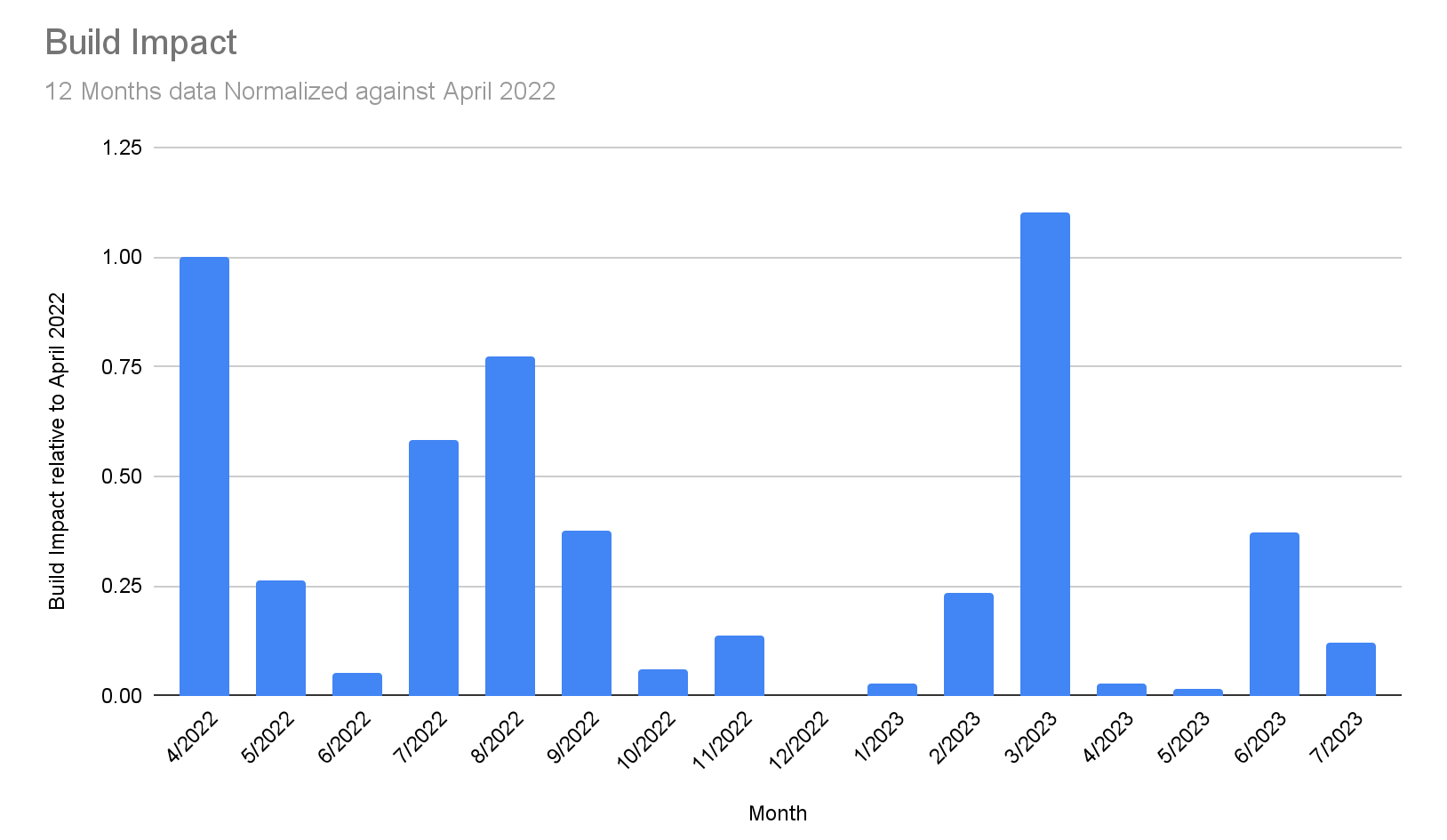
Build impact
Because minutes of incident duration doesn’t present the whole picture of your experience as a customer, we also measure build impact. By weighing our incident time by the amount that it impacts the most important thing that you do (building) and by tracking this number, we ensure we’re focused on the outcomes that matter. We’ve seen a solid improvement over the last few months (minus March, which we previously covered). There is more good than bad here, which signals what we’re learning and doing as a result is working.
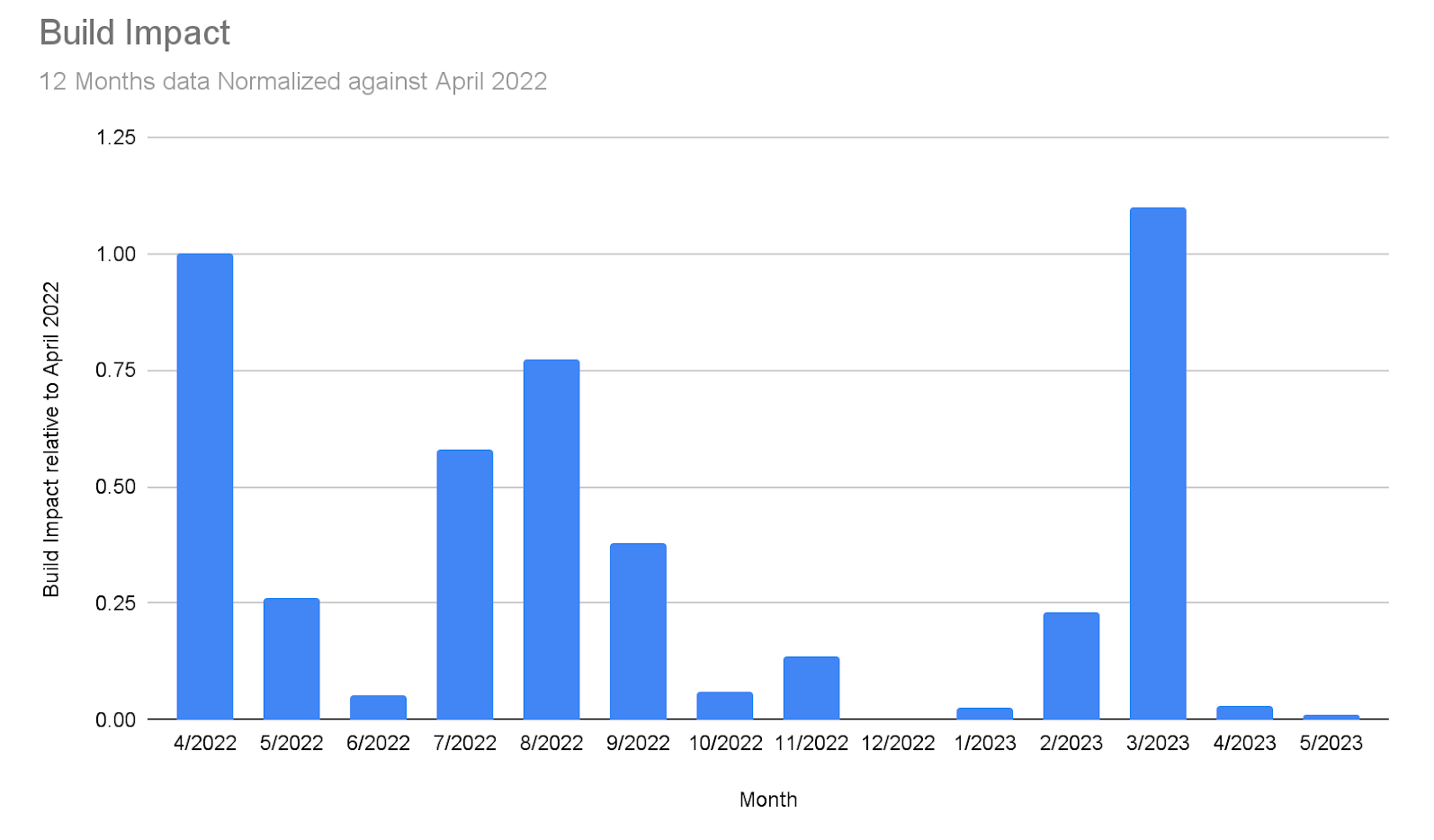
Note: In review of our data, we uncovered previously unaccounted-for build impact in March and have adjusted this chart to reflect that.
The investments we’ve made are paying off. The work we’ve done to protect the critical path, improve our observability tools, and take a system-view has reaped a number of good months and strengthened our confidence in the way forward.
In our next update, we’ll share some specific details of the changed behaviors in our system that have resulted from our investments.
Reliability update 2023-04-14
Our focus on reliability continues. We’re making progress and are learning a lot, but there is certainly more work to be done.
How do we know? We’ve been going deep into the data to get a more nuanced understanding of where we can improve. In our last update, we committed to sharing the numbers to show how we think about reliability and what our key results have been.
While any disruption is something we’d like to avoid, we’ve been ruthlessly focused on reducing incident length, specifically those disruptions that run over 60 minutes.
Beyond that, we’re hyper-focused on making sure that, even in the case of a disruption somewhere in our system, you can still build. We’ve been protecting this critical path, and prioritizing work that minimizes customer impacts. We call this measurement “build impact.”
Here’s what the data tells us
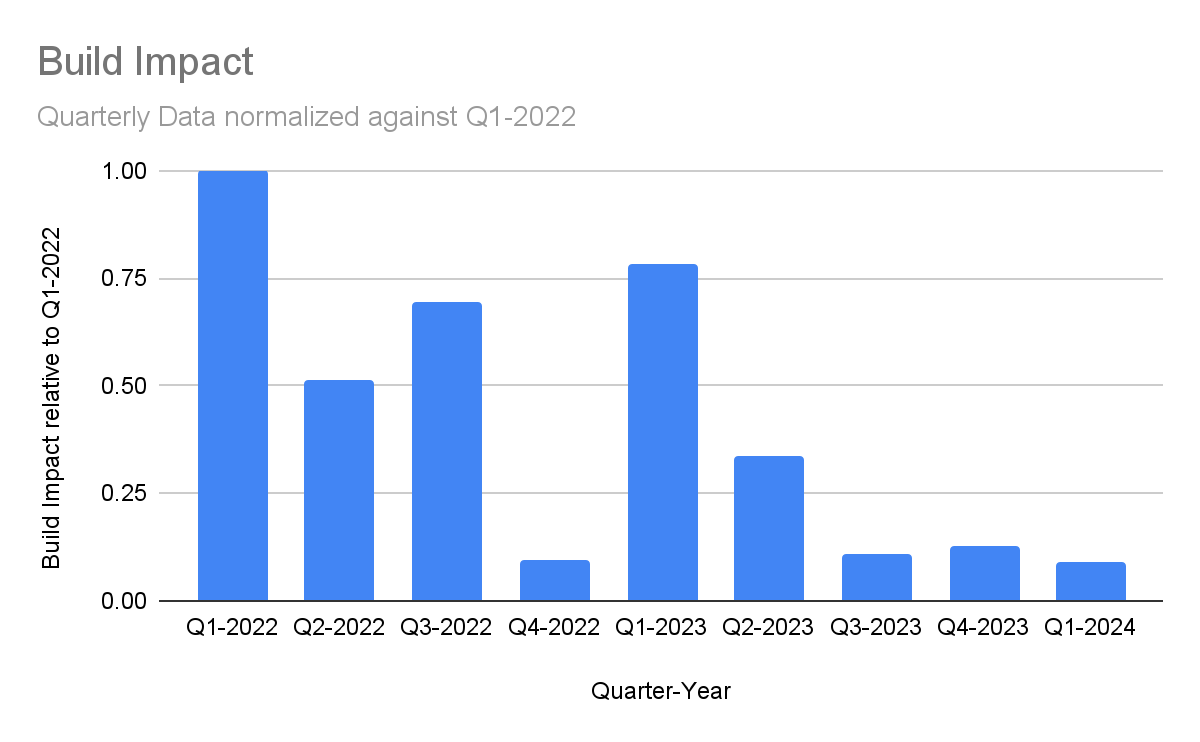
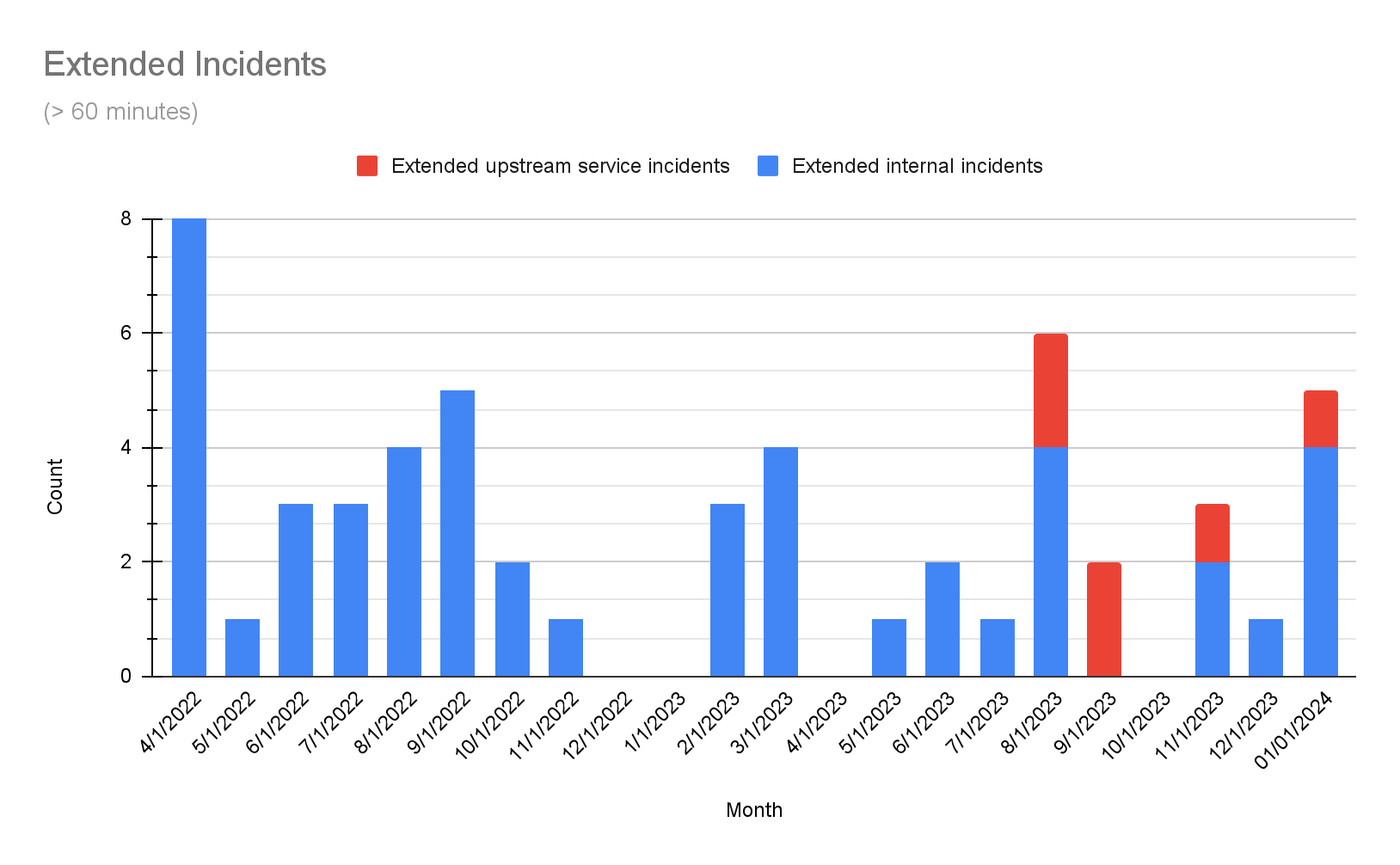
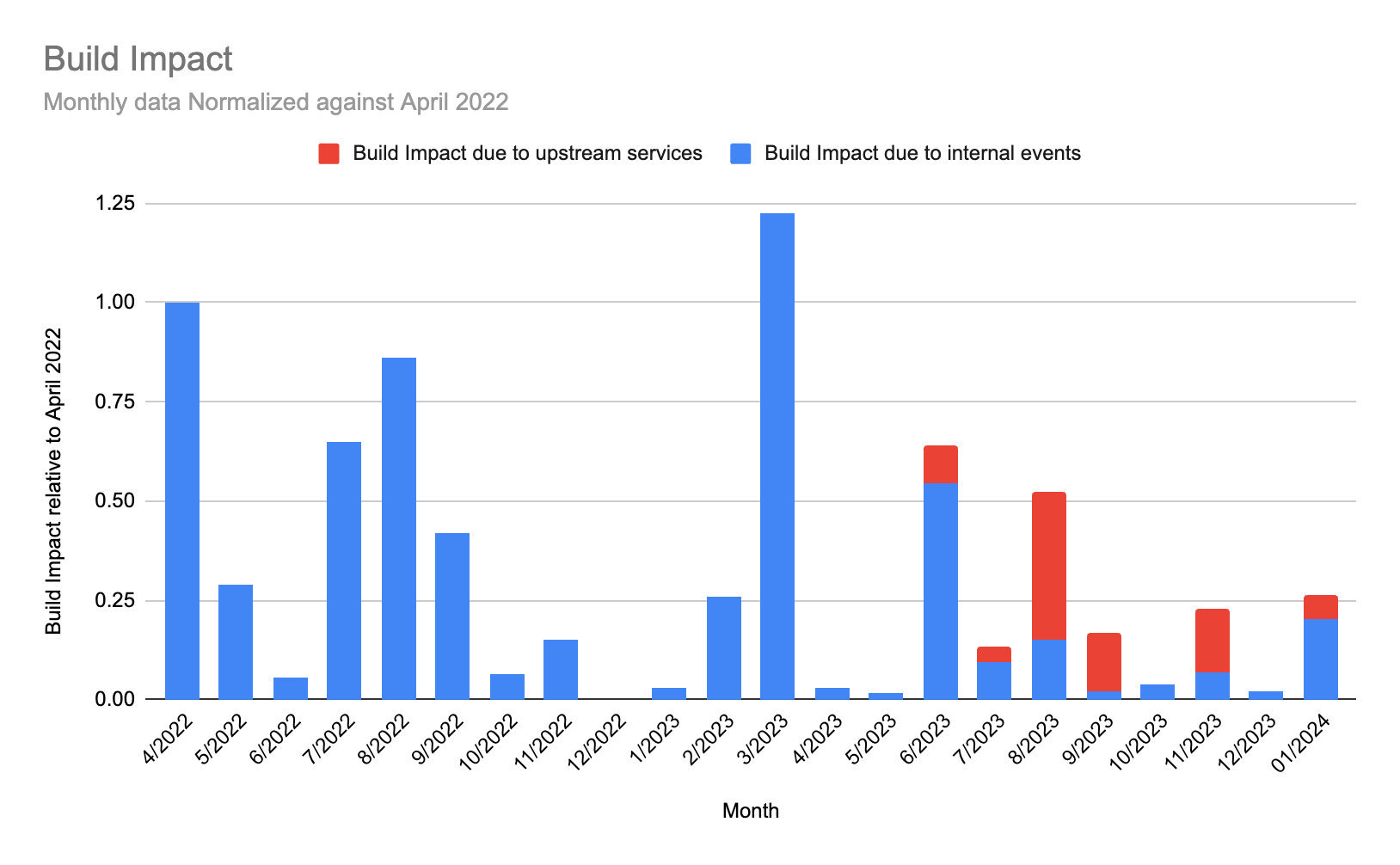
The chart below labeled Extended Incidents represents the number of incidents that were over 60 minutes in duration. While we want to see that number near or at “0”, the trend is going down since last April. During this time, we heavily invested in our ability to respond to incidents by ensuring the entire team had a more thorough understanding of the complexity of our distributed system, so they could make decisions that were informed by this system view.
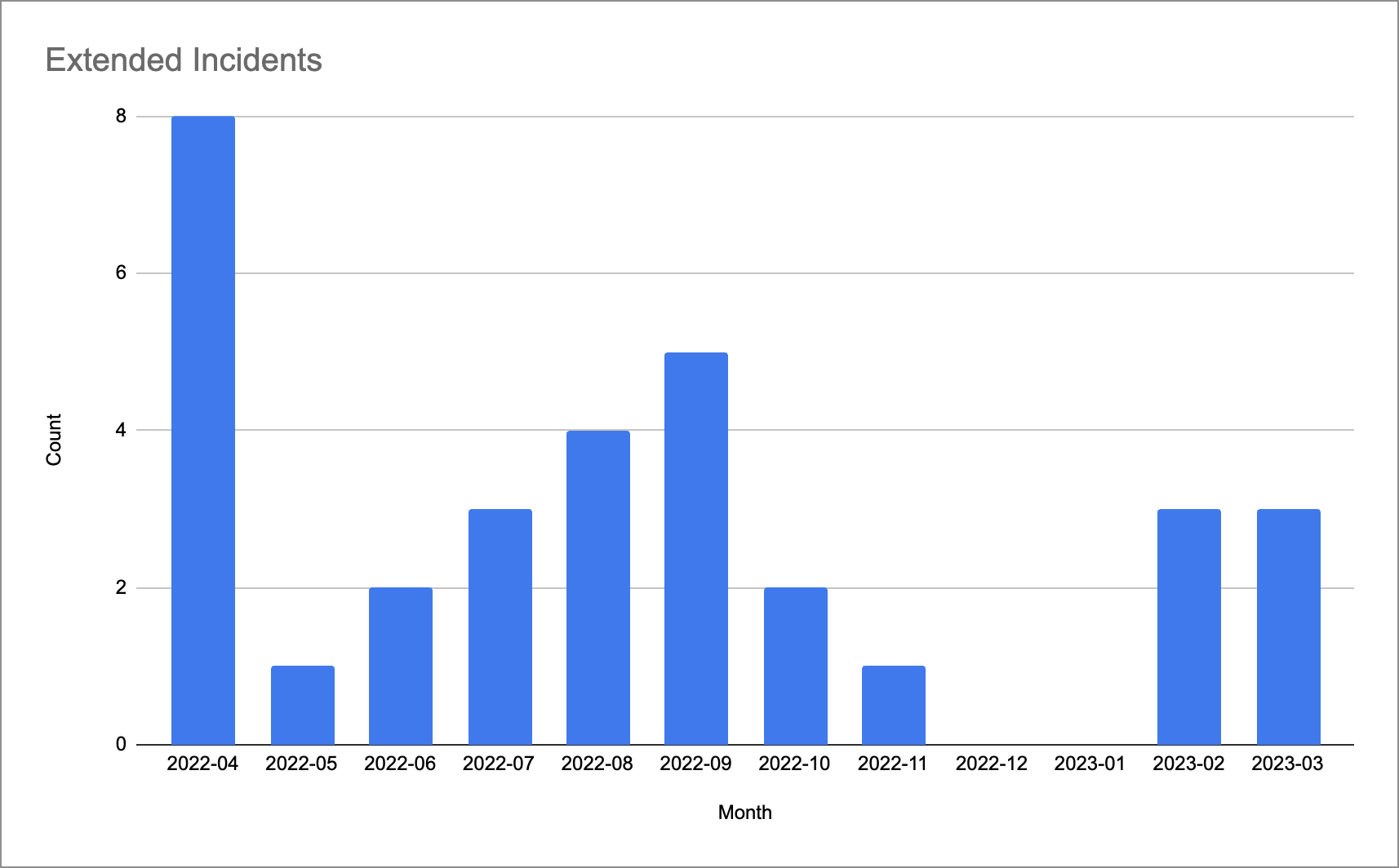
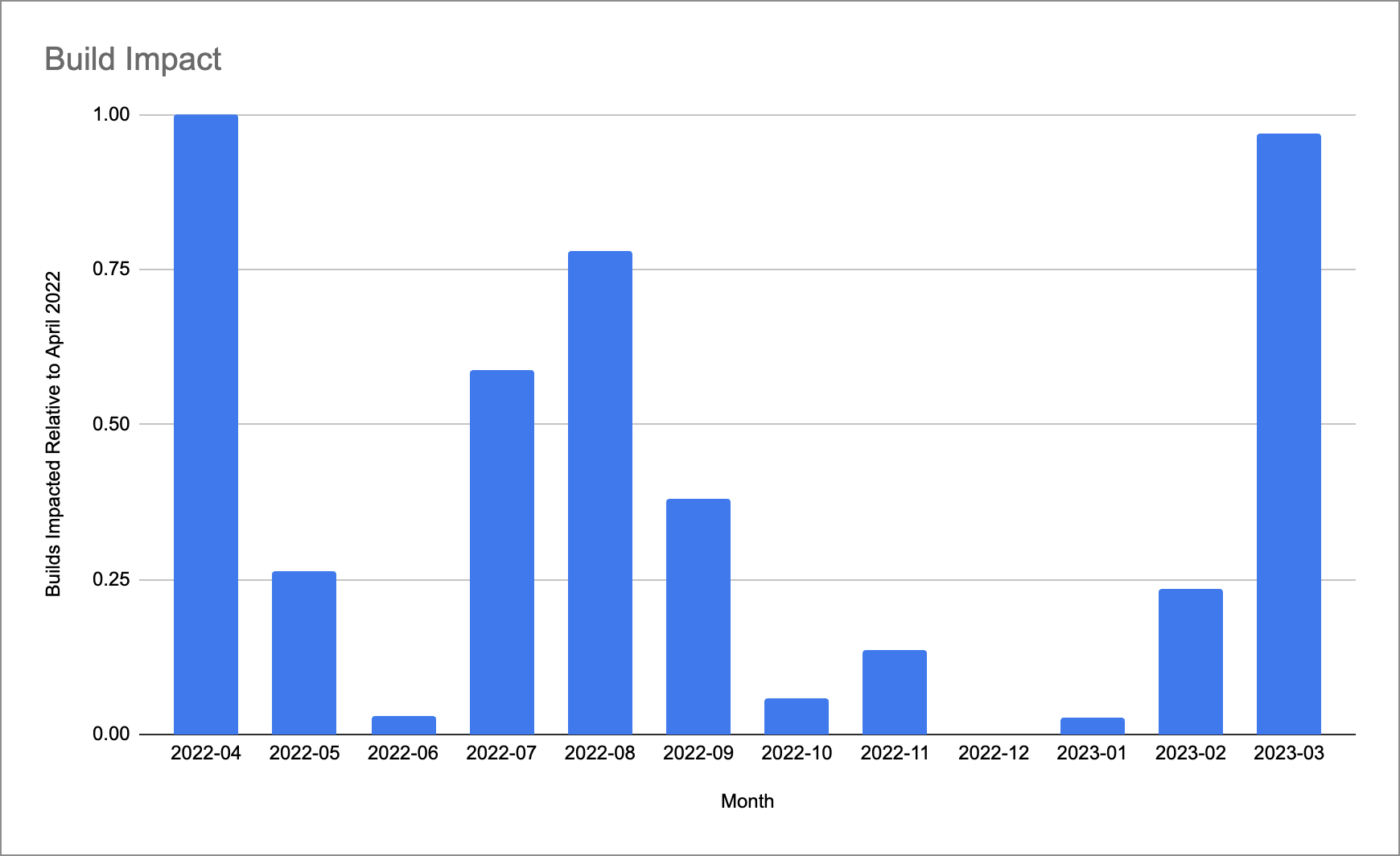
The second chart (below), labeled Build Impact, shows the impact on builds from the incidents that occured over the past 12 months, normalized against the start of the period (April 2022). On the graph, April’s level of build impact is measured as “1”, with our goal to be near or at “0.” After April 2022, we had some success by prioritizing our ability to isolate sections of our system to protect the critical path and keep you building.
Unfortunately, March 2023 was a challenging month, caused by an issue with a Kubernetes upgrade. You can read more details here.
Here’s where we’re headed
The goal is to raise our confidence level, continue limiting the blast radius of production infrastructure changes and test as thoroughly as possible. For Kubernetes, and across our infrastructure, we are improving our upgrade strategies to meet our standards for risk, and will have new paths in place before we perform another upgrade to our main production clusters.
What do I want you to take away from this? I’ve been bringing you regular updates because continuously improving our platform’s reliability is a vital part of how we deliver value to you, our customers. This work is also hard, and complex. When speaking to fellow software engineers, I know you know that.
We know that when we focus on something, we can make it better. But I’m here reporting, not celebrating. There’s more to do, and above all I want you to know we’re still dedicated to the cause.
We’ll keep doing the work; thanks for being here.
Rob
Reliability update 2023-01-30
I’ve been coming to you with reliability updates for the last four months, sharing with you our wins and challenges, and what we’ve been doing behind the scenes to ensure our platform is ready to build anytime you are.
This month, we experienced a security incident that derailed many of your teams’ abilities to do just that.
So, despite reliability being up over the last month, I want to keep this short, and leave you with two things:
- Our number one priority for this moment is to stay focused on the aftermath of the incident, working with our customers to ensure your pipelines are secure and your secrets are rotated. We’ll be doing this for as long as it takes, but once we return to business as usual, I’ll be back with a more numbers-focused update, bringing you substantive metrics you can take as indicators of the work we’ve been doing.
- As I think about systems, reliability and security actually converge: things that make us more reliable also make us more secure. So doing the work we’ve done to increase reliability (i.e. more cleanly segregate parts of our system, maintain third-party verified audit points and logging) also enhanced our ability to recover from our security incident. Both security and reliability are required for you to do your job, and our goal is to continue to raise the bar on having highly secure, highly available systems.
If you haven’t rotated your secrets yet, please do so. If you have, thank you.
Rob
Reliability update 2022-12-21
In the last couple of updates I’ve talked about some of the actions we’ve been taking to build longer-term reliability at the core of our service. In this update, I wanted to describe a bit of how we identified the underlying issues. Specifically, orienting around systemic issues, whether they are organizational or architectural.
Like many organizations, at CircleCI we have a “you build it, you run it” approach to software delivery, meaning teams are responsible for the full lifecycle of their own delivery streams. We also have shared practices for incident investigation and follow-up. However, with teams capable of managing this full lifecycle on their own, we started missing more systemic problems, thinking they were only present in the individual teams that were handling the follow-up.
Earlier this year, we turned our attention to those systemic issues by aggregating data from all of our sources. This included looking across post-incident reports, the associated historical data, and all of the follow-up work that had been done by individual teams. Inventorying all the data was important, but what stood out was what it took to get to this aggregate view needed to make changes.
Most of our tooling is oriented towards individual incidents rather than that aggregate review. Even the tools that showed data across incidents didn’t expose what we wanted. We looked at everything from where time was being spent in incident response to the classifications of causes so we could organize ourselves and our systems for highest impact.
While we were able to do most of the aggregation in a spreadsheet, much of post-incident follow-up is very narrative driven. Doing the work of structuring that historical data enough to draw conclusions was hard but has been very helpful in seeing the bigger picture. We were able to see things that weren’t clear from reading one incident report or by having a deep dive with one of our teams.
All of this work highlighted an interesting tension of maintaining our fast-moving, stream-aligned DevOps culture while bringing in a vantage point to eliminate system-wide challenges for our teams. This work provided us clearer insights into where we needed to address issues that were found in our organization or our architecture (or both). As a result, we are mitigating problems that are more systemic in nature, and providing guardrails so our teams can still move quickly and own what they build. With this aggregate view, we’re making progress on seeing and addressing points of failure before they occur.
To better building,
Rob Zuber
rob@circleci.com
Reliability update 2022-10-27
Last month, I made a commitment to you that I’d bring you updates on our reliability work: how it’s going, what’s working, and where we still have work to do.
I’d like to achieve three goals through these updates:
- Reinforce our ongoing commitment to reliability,
- Share more of our reliability roadmap, so you have broader context to any future updates we share on this work, and
- Be transparent about our work and insights, so that the community can also benefit from our experiences on this journey.
In the software community, we all suffer when services go down, but we advance together by sharing our learnings.
Last month (scroll down for the full update), I shared that we’d been working on isolating parts of our platform in order to protect customers’ builds and keep them running.
Today, I want to share more detail about our current approach: system isolation in order to protect your builds no matter what. I want to emphasize that this isn’t simply something we did and reported on, but the principle of protecting builds will guide us through both upcoming reliability investments, as well as all new development work on the platform.
Like all platforms, we got here through evolution, so let me walk you through an (abridged) history of the CircleCI platform.
We started out with a monolith, like so many other companies. By default, in a monolith all your work is commingled. This necessarily creates coupling, and that leads to the potential for failures to cascade. With no separation, a failure somewhere in your codebase can lead to a failure anywhere else.
As we broke apart the monolith, we did so based on work stages, or what was happening at different points (such as workflow orchestration and job execution). That approach simplified our codebases and made delivery easier, but within those stages, we have a combination of active work and historical reporting on that work.
The work we’re doing now is to isolate at each of these stages, such that every component that is involved in running active builds can be protected from anything else.
We’re doing this work incrementally to ensure rapid results while minimizing disruptions. The first stage involved simple tools, like functions to disable historical viewing if needed. This creates a release valve.
We have also increased our use of read-only replicas for historical queries. And we are leveraging split deployments of some of these services to isolate compute resources even when the code is shared.
The next stage that we are moving into involves separating systems completely. In other words, code paths and data for real-time builds vs code paths and data for history. While replicas are helpful in distributing load, they require that all stores have the same volume of data. This can be solved with sharding, but even then you are stuck with a schema design that is trying to support both access patterns. When they are fully separate, we can optimize each design, both for scale and for product capabilities. We’re early in that approach but we’re again taking incremental steps to start realizing gains as quickly as possible.
This brings us to a good question: why didn’t we do this at the outset? Well, this is a need of scale, and doing it right out of the gate would be a mistake. Why? When you first create a platform like ours, and make early architecture decisions, I believe it’s incredibly important to make decisions that enable you to pivot quickly, and respond to the demands of your early customers. You don’t know what they’ll want, and therefore you don’t know what features your team will go on to build in order to support and delight those customers. It was possible at the beginning to imagine we’d face a project like this eventually, but I don’t think it’s possible to know which of an infinite set of scale tipping points we’d reach.
In all, what I’d like you to take from this update is that we are taking this seriously, and approaching it the way we approach all our work: incrementally, and with your needs at the core of our decisions. While we don’t want systems to break, it happens. Better isolation means we can march toward the real goal: ensuring your builds run, every day, no matter what else may be going on in our platform or the larger ecosystem.
If you’re curious about our incremental steps on this journey, check back here for updates. And if not, that’s fine too; get back to building the things that support and delight your customers, but we wanted you to know what is going on behind the scenes at CircleCI.
To better building,
Rob Zuber
rob@circleci.com
Reliability update 2022-09-19
Last week, the pipelines page was unavailable for a significant portion of a day. This prevented many teams from managing their work as expected. As an engineer and as a leader, I know how important it is to stay in flow, and have your tools there when you need them. We’re sorry for the disruption caused to your team’s work.
As I stated back in April (full post follows), my top priority as CTO is reducing the length and impact of incidents at CircleCI.
But when things look like they did last week, the headway we’ve made may not be apparent.
In addition to focusing on diagnostic speed since our original post, we’ve begun investing in protecting your ability to get work done (namely, run pipelines), even when things break. While our work is still in progress, we’ve made some key gains. But if you can’t see or feel the impact of this work so far, then we’re not succeeding. Not as a technical team, and not at creating the trusting relationship we want to build with you.
One gain worth noting is the work the team has done to begin segregating parts of our architecture. This lets us constrain incident impact and protect your pipelines when things otherwise go sideways. It allowed us to do things like temporarily shut off bits of the UI in order to make sure that pipelines could still run, which is what we did last week. But we didn’t share that with you. Instead, you saw that the site was down, and reasonably assumed that nothing had changed.
Again, we have more work to do here, and we remain deeply invested in it. We can’t stop things from breaking, but we can continue to find new ways to ensure your builds can always run, and give you better and more timely information about how to accomplish your work, even when Plan A fails.
Additionally, it’s been 5 months since our last reliability update, and we can do better. Going forward, I’m committing to updating you on our new reliability developments. I welcome your feedback in the meantime.
Reliability update 2022-04-13
At CircleCI, our mission is to manage change so software teams can innovate faster. But lately, we know that our reliability hasn’t met our customers’ expectations. As the heart of our customers’ delivery pipelines, we know that when we go down, your ability to ship grinds to a halt as well. We’re sorry for the disruptions to your work and apologize for the inconvenience to you and your team.
What’s been happening
No single part of our platform or infrastructure is at fault for recent outages. Instead, we’ve seen a mix of sources of issues, from bug-causing updates to dependency issues, and upstream provider instability. The January update to our pricing plan brought increased traffic and usage to our platform. While we planned and modeled for this, it has contributed to us reaching inflection points in some of our systems.
While there is no clear pattern in the cause of recent incidents, we know our overall time to resolution has been too long. Diving into our incident response protocol has helped us uncover places where our team execution under pressure has not helped us. We fully embrace blameless engineering culture and the DevOps principle of “you build it, you run it,” but the distributed nature of both our system and our teams has made that connection, communication, and resolution difficult.
Why? Over the past 12 months, we’ve nearly doubled our engineering team. This growth has been intentional and provided some incredible velocity - last week alone we deployed over 850 times. But that growth also means our base of intuitive knowledge has become less central and cohesive. We need to rebuild both broad and deep systems understanding across all of our teams.
What we’re doing to move forward
For us, technology is all about people, and improving our reliability will take a people-first approach. As of last week, we’ve created a tiger team of on-call first responders, including myself, on on-call rotation. This is a global team of individuals empowered to both fix things quickly and effect long-term change through both process and technology. Our goal is to strengthen the impact of engineers who can drive an incident from identification to resolution and then help share insights with the larger team.
Historically, we’ve focused our reliability efforts on system “hot spots” that were known sources of downtime, including fleet management and machine provisioning. We’ve made deep investments there that have paid off. But as our organization has grown, our issues have been less about service-level disruptions, and more about the complex interactions of a large distributed system. Our goal for this tiger team is to get you back to working as quickly as possible, then use what we learn to resolve the underlying causes of those incidents.
We’re also making investments to our platform to build and rebuild with the future in mind. We recently hired a new chief architect to lead our efforts in platform scalability and building for long-term product innovation.
How you will know we’re making progress
While it would be unwise (and unbelievable!) to promise that we will never have another incident, we can commit to making them less of a burden for our customers.
As we continue to invest in our long-term platform stability, our short-term focus is on reducing incident length. For incidents where customer impact exceeds one hour, we commit to publishing an incident report on status.circleci.com.
As CTO, improving incident response is my top priority. We know we have work to do here, and we’re confident that the plans and team we have in place will help us make immediate improvements. Thank you to our customers and community for your ongoing support and patience.





