Using Workflows to orchestrate jobs
On This Page
- Overview
- States
- Workflows configuration examples
- Concurrent job execution
- Sequential job execution
- Fan-out/fan-in workflow
- Hold a workflow for a manual approval
- Scheduling a workflow
- Nightly example
- Specifying a valid schedule
- Using contexts and filtering in your workflows
- Using job contexts to share environment variables
- Branch-level job execution
- Executing workflows for a git tag
- Using regular expressions to filter tags and branches
- Using workspaces to share data between jobs
- Rerunning a workflow’s failed jobs
- Troubleshooting
- Workflow and subsequent jobs do not trigger
- Rerunning workflows fails
- Workflows waiting for status in GitHub
- See also
Workflows help you increase the speed of your software development through faster feedback, shorter reruns, and more efficient use of resources. This document describes the workflows feature and provides example configurations.
Overview
A workflow is a set of rules for defining a collection of jobs and their run order. Workflows support complex job orchestration using a simple set of configuration keys to help you resolve failures sooner.
With workflows, you can:
-
Run and troubleshoot jobs independently with real-time status feedback.
-
Schedule workflows for jobs that should only run periodically.
-
Fan-out to run multiple jobs concurrently for efficient version testing.
-
Fan-in to quickly deploy to multiple platforms.
For example, if only one job in a workflow fails, you will know it is failing in real-time. Instead of wasting time waiting for the entire workflow to fail and rerunning the entire job set, you can rerun just the failed job.
States
Workflows may appear with one of the following states:
| State | Description |
|---|---|
RUNNING | Workflow is in progress |
NOT RUN | Workflow was never started |
CANCELED | Workflow was canceled before it finished |
FAILING | A job in the workflow has failed |
FAILED | One or more jobs in the workflow failed |
SUCCESS | All jobs in the workflow completed successfully |
NEEDS APPROVAL | A job in the workflow is waiting for approval |
NEEDS SETUP | A workflow stanza is not included or is incorrect in the |
Workflows configuration examples
For a full specification of the workflows key, see the Workflows section of the Configuration Reference. |
To run a set of concurrent jobs, add a new workflows: section to the end of your existing .circleci/config.yml file with the version and a unique name for the workflow.
Concurrent job execution
The following sample .circleci/config.yml file shows the default workflow orchestration with two concurrent jobs. It is defined by using the workflows key named build_and_test, and by nesting the jobs key with a list of job names. The jobs have no dependencies defined, so they will run concurrently.
| Using Docker? Authenticating Docker pulls from image registries is recommended when using the Docker execution environment. Authenticated pulls allow access to private Docker images, and may also grant higher rate limits, depending on your registry provider. For further information see Using Docker authenticated pulls. |
jobs:
build:
docker:
- image: cimg/base:2023.06
steps:
- checkout
- run: <command>
test:
docker:
- image: cimg/base:2023.06
steps:
- checkout
- run: <command>
workflows:
build_and_test:
jobs:
- build
- testSee the Sample concurrent workflow config for a full example.
When using workflows, try to do the following:
-
Move the quickest jobs up to the start of your workflows. For example, lint or syntax checking should happen before longer-running, more computationally expensive jobs.
-
Using a "setup" job at the start of a workflow can be helpful to do some preflight checks and populate a workspace for all the following jobs.
Consider reading the Optimization overview for more tips related to improving your configuration.
Sequential job execution
The following example shows a workflow with four sequential jobs. The jobs run according to configured requirements, each job waiting to start until the required job finishes successfully as illustrated in the diagram.
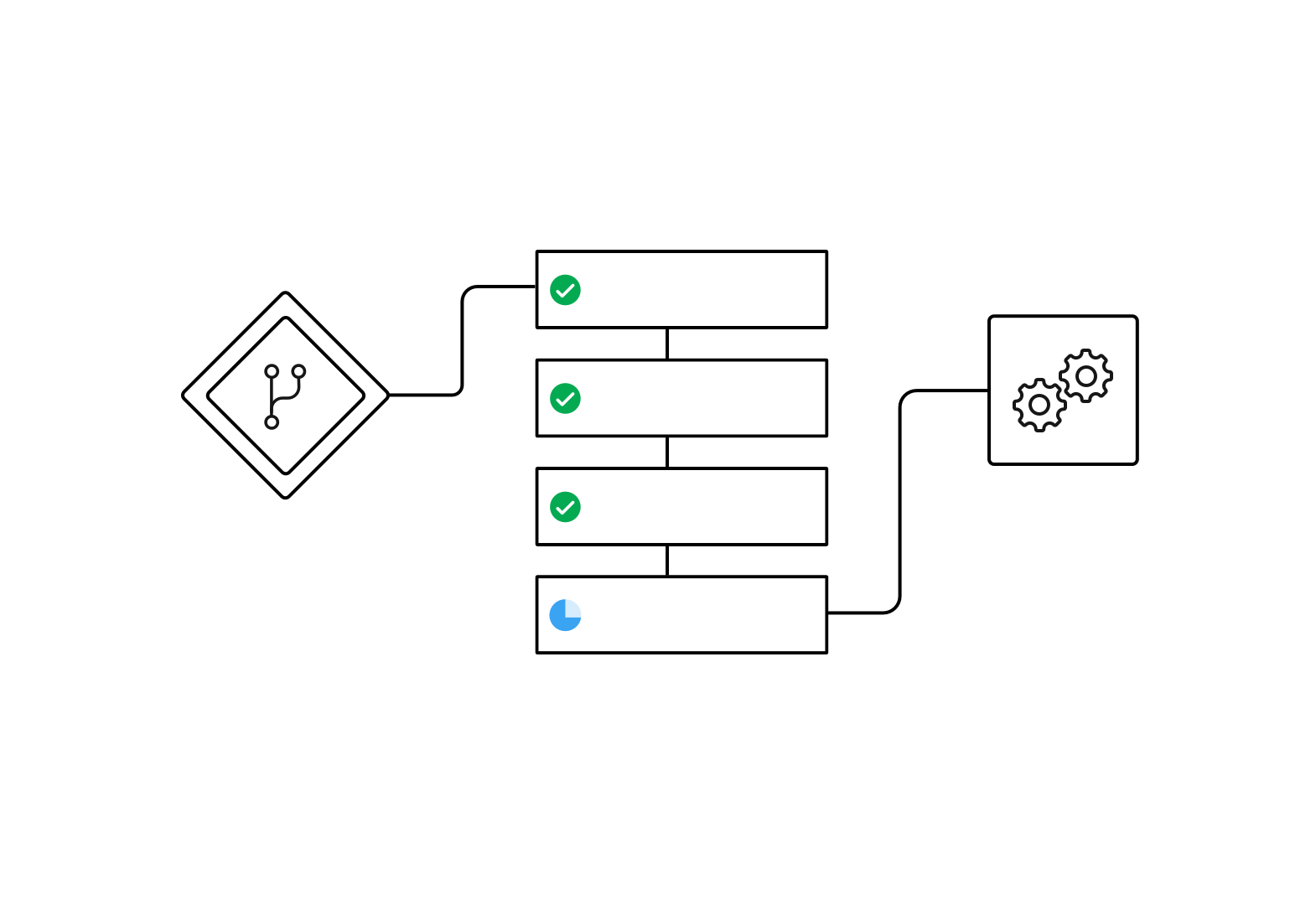
The following config.yml snippet is an example of a workflow configured for sequential job execution:
workflows:
build-test-and-deploy:
jobs:
- build
- test1:
requires:
- build
- test2:
requires:
- test1
- deploy:
requires:
- test2The dependencies are defined by setting the requires key as shown. The deploy job will not run until the build and test1 and test2 jobs complete successfully. A job must wait until all upstream jobs in the dependency graph have run. So, the deploy job waits for the test2 job, the test2 job waits for the test1 job and the test1 job waits for the build job.
See the Sample Sequential Workflow config for a full example.
Fan-out/fan-in workflow
The illustrated example workflow runs a common build job, then fans-out to run a set of acceptance test jobs concurrently, and finally fans-in to run a common deploy job.
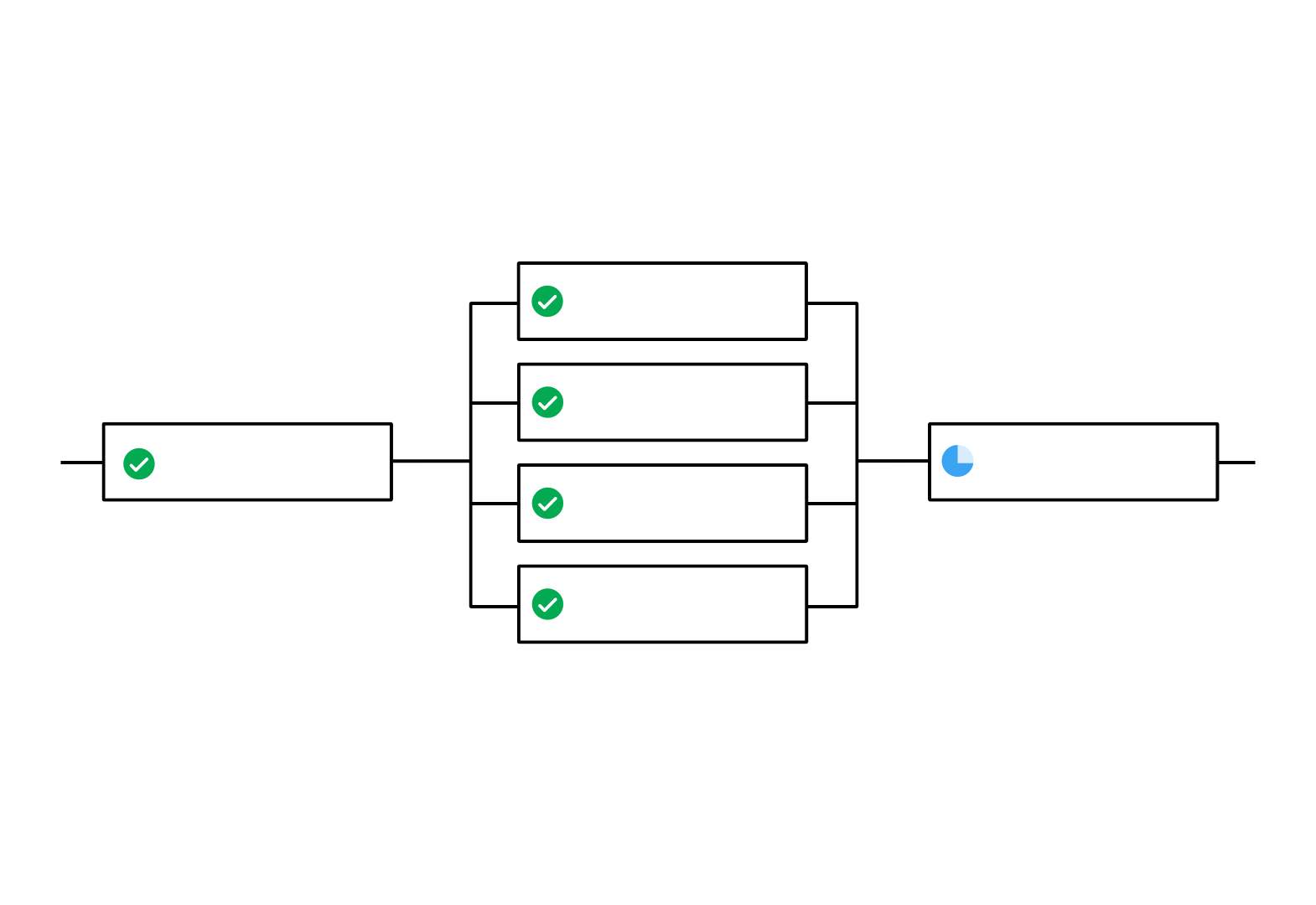
The following config.yml snippet is an example of a workflow configured for fan-out/fan-in job execution:
workflows:
build_accept_deploy:
jobs:
- build
- acceptance_test_1:
requires:
- build
- acceptance_test_2:
requires:
- build
- acceptance_test_3:
requires:
- build
- acceptance_test_4:
requires:
- build
- deploy:
requires:
- acceptance_test_1
- acceptance_test_2
- acceptance_test_3
- acceptance_test_4In this example, as soon as the build job finishes successfully, all four acceptance test jobs start. The deploy job must wait for all four acceptance test jobs to complete successfully before it starts.
See the Sample Fan-in/Fan-out Workflow config for a full example.
Hold a workflow for a manual approval
Configure a workflow to wait for manual approval before continuing using an approval job. Anyone who has push access to the repository can click the Approve button in the CircleCI web app to continue the workflow.
To set up a manual approval workflow, add a job to the jobs list of your workflow with type: approval. For example:
# ...
# << your config for the build, test1, test2, and deploy jobs >>
# ...
workflows:
build-test-and-approval-deploy:
jobs:
- build # your custom job from your config, that builds your code
- test1: # your custom job; runs test suite 1
requires: # test1 will not run until the `build` job is completed.
- build
- test2: # another custom job; runs test suite 2,
requires: # test2 is dependent on the success of job `test1`
- test1
- hold: # <<< A job that will require manual approval in the CircleCI web application.
type: approval # This key-value pair will set your workflow to a status of "Needs Approval"
requires: # We only run the "hold" job when test2 has succeeded
- test2
# On approval of the `hold` job, any successive job that requires the `hold` job will run.
# In this case, a user is manually triggering the deploy job.
- deploy:
requires:
- holdThe outcome of the above example is that the deploy job will not run until you click the hold job in the Workflows page of the CircleCI app and then click Approve. In this example, the purpose of the hold job is to wait for approval to begin deployment. A job can be approved for up to 90 days after being issued.
Some things to keep in mind when using manual approval in a workflow:
-
approvalis a special job type that is only available to jobs under theworkflowkey -
The
holdjob must be a unique name not used by any other job. That is, your custom configured jobs, such asbuildortest1in the example above wouldn’t be given atype: approvalkey. -
The name of the job to hold is arbitrary - it could be
waitorpause, for example, as long as the job has atype: approvalkey. -
All jobs that are to run after a manually approved job must
requirethe name of the approval job. Refer to thedeployjob in the above example. -
Jobs run in the order defined until the workflow processes a job with the
type: approvalkey followed by a job on which it depends.
The following screenshot demonstrates a workflow the needs approval, the approval popup, and the resulting workflow map once approved.
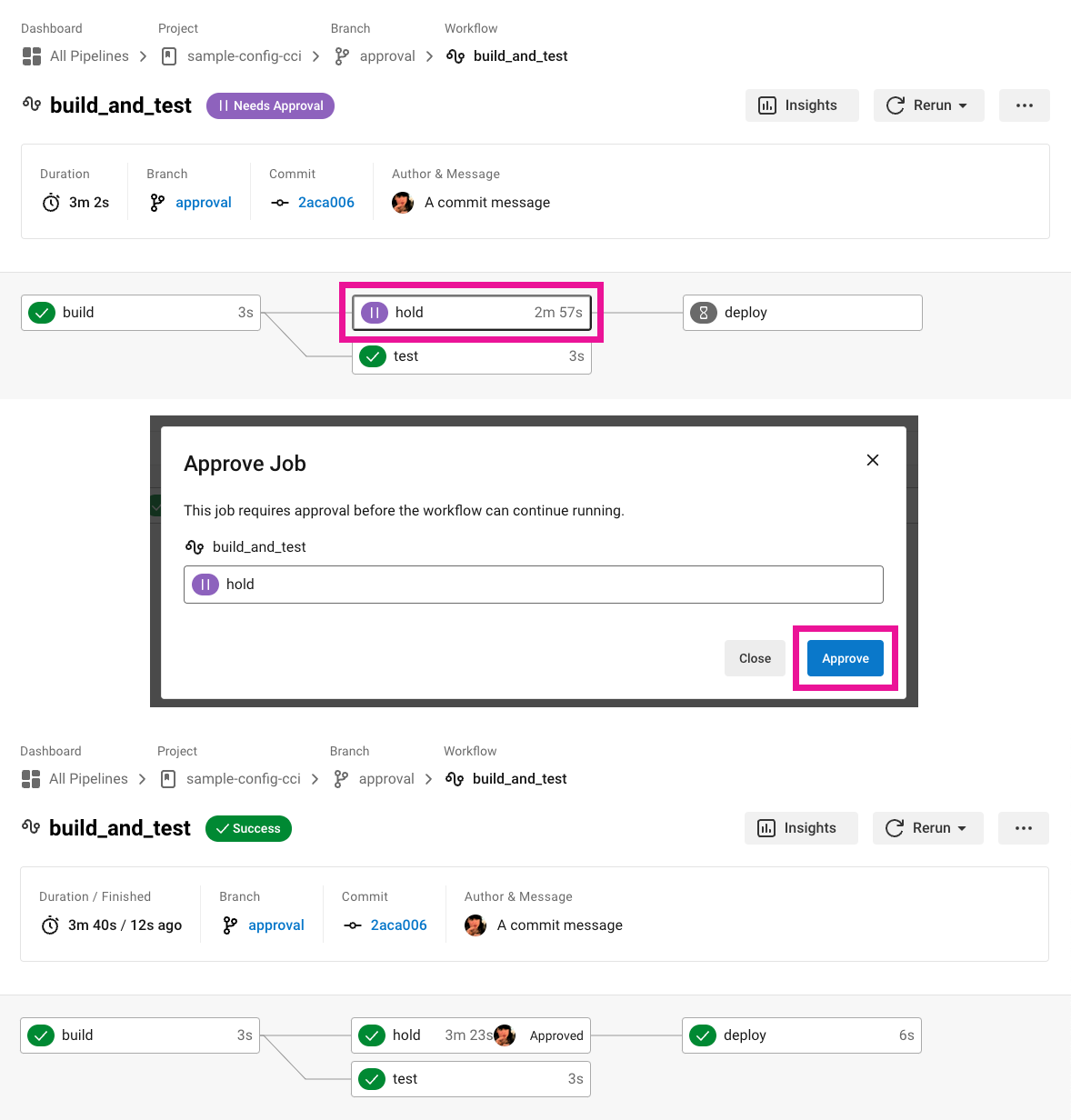
By clicking on the approval job’s name (hold, in the screenshot above), an approval dialog box appears requesting that you approve the approval job. You can also choose to close the popup without approving.
After approving, the rest of the workflow runs as configured.
Scheduling a workflow
| The deprecation of the scheduled workflows feature has been postponed. Since the deprecation announcement went live, your feedback and feature requests have been monitored and it is clear there is more work to do in order to improve the existing scheduled pipelines experience, and also make migration easier for all. Updates on a new deprecation timeline will be announced here and on CircleCI Discuss. |
Running a workflow for every commit for every branch can be inefficient and expensive. Instead, you can schedule a workflow to run at a certain time for specific branches. This will disable commits from triggering jobs on those branches.
Consider running workflows that are resource-intensive or that generate reports on a schedule rather than on every commit by adding a triggers key to the configuration. The triggers key is only added under your workflows key. This feature enables you to schedule a workflow run by using cron syntax to represent Coordinated Universal Time (UTC) for specified branches.
If you do not configure any workflows in your .circleci/config.yml, an implicit workflow is used. If you declare a workflow to run a scheduled build, the implicit workflow is no longer run. You must add your workflow to your config.yml in order for CircleCI to also build on every commit.
| When you schedule a workflow, the workflow will be counted as an individual user seat. |
Nightly example
By default, a workflow is triggered on every git push. To trigger a workflow on a schedule, add the triggers key to the workflow and specify a schedule.
In the example below, the nightly workflow is configured to run every day at 12:00am UTC. The cron key is specified using POSIX crontab syntax, see the crontab man page for cron syntax basics. The workflow will be run on the main and beta branches.
| Scheduled workflows may be delayed by up to 15 minutes. This is done to maintain reliability during busy times such as 12:00am UTC. Do not assume that scheduled workflows are started with to-the-minute accuracy. |
workflows:
commit:
jobs:
- test
- deploy
nightly:
triggers:
- schedule:
cron: "0 0 * * *"
filters:
branches:
only:
- main
- beta
jobs:
- coverageIn the above example, the commit workflow has no triggers key and will run on every git push. The nightly workflow has a triggers key and will run on the specified schedule.
Specifying a valid schedule
A valid schedule requires a cron key and a filters key.
The value of the cron key must be a valid crontab entry.
The following are not supported:
-
Cron step syntax (for example,
/1,/20). -
Range elements within comma-separated lists of elements.
-
Range elements for days (for example,
Tue-Sat).
Use comma-separated digits instead.
Example invalid cron range syntax:
triggers:
- schedule:
cron: "5 4 * * 1,3-5,6" # < the range separator with `-` is invalidExample valid cron range syntax:
triggers:
- schedule:
cron: "5 4 * * 1,3,4,5,6"The value of the filters key must be a map that defines rules for execution on specific branches.
For more details, see the branches section of the Configuring CircleCI document.
For a full configuration example, see the Sample Scheduled Workflows configuration.
Using contexts and filtering in your workflows
The following sections provide example for using Contexts and filters to manage job execution.
Using job contexts to share environment variables
The following example shows a workflow with four sequential jobs that use a context to share environment variables. See the Contexts document for detailed instructions on this setting in the application.
The following config.yml snippet is an example of a sequential job workflow configured to use the resources defined in the org-global context:
workflows:
build-test-and-deploy:
jobs:
- build
- test1:
requires:
- build
context: org-global
- test2:
requires:
- test1
context: org-global
- deploy:
requires:
- test2The environment variables are defined by setting the context key as shown to the default name org-global. The test1 and test2 jobs in this workflows example will use the same shared environment variables when initiated by a user who is part of the organization. By default, all projects in an organization have access to contexts set for that organization.
Branch-level job execution
The following example shows a workflow configured with jobs on three branches: Develop, Stage, and Pre-Prod. Workflows will ignore branches keys nested under jobs configuration, so if you use job-level branching and later add workflows, you must remove the branching at the job level and instead declare it in the workflows section of your .circleci/config.yml, as follows:
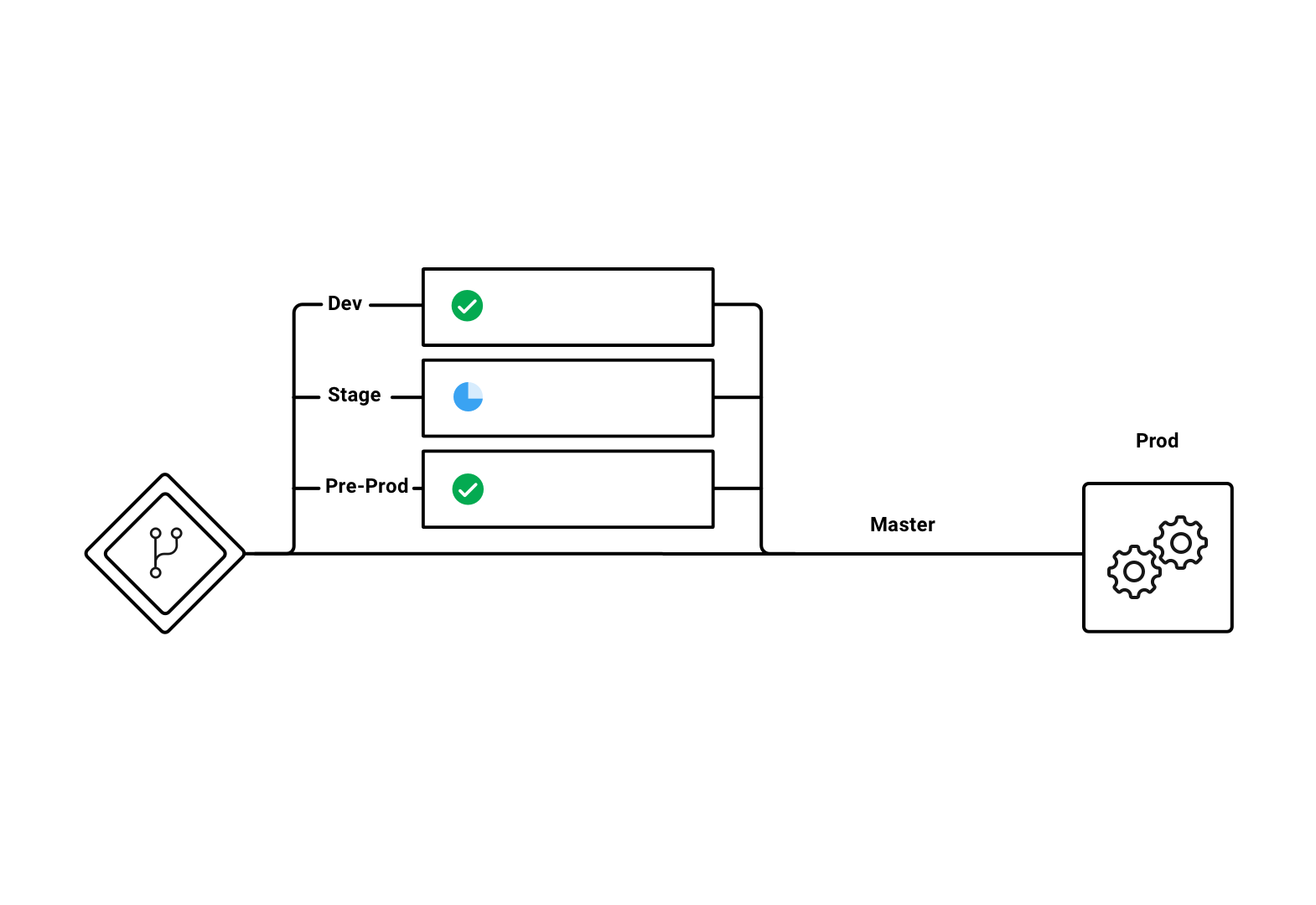
The following .circleci/config.yml snippet is an example of a workflow configured for branch-level job execution:
workflows:
dev_stage_pre-prod:
jobs:
- test_dev:
filters: # using regex filters requires the entire branch to match
branches:
only: # only branches matching the below regex filters will run
- dev
- /user-.*/
- test_stage:
filters:
branches:
only: stage
- test_pre-prod:
filters:
branches:
only: /pre-prod(?:-.+)?$/For more information on regular expressions, see the Using Regular Expressions to Filter Tags And Branches section below.
For a full example of workflows, see the configuration file for the Sample Sequential Workflow With Branching project.
Executing workflows for a git tag
CircleCI does not run workflows for tags unless you explicitly specify tag filters. Additionally, if a job requires any other jobs (directly or indirectly), you must use regular expressions to specify tag filters for those jobs. Both lightweight and annotated tags are supported.
In the example below, two workflows are defined:
-
untagged-buildruns thebuildjob for all branches. -
tagged-buildrunsbuildfor all branches and all tags starting withv.
workflows:
untagged-build:
jobs:
- build
tagged-build:
jobs:
- build:
filters:
tags:
only: /^v.*/In the example below, two jobs are defined within the build-n-deploy workflow:
-
The
buildjob runs for all branches and all tags. -
The
deployjob runs for no branches and only for tags starting with 'v'.
workflows:
build-n-deploy:
jobs:
- build:
filters: # required since `deploy` has tag filters AND requires `build`
tags:
only: /.*/
- deploy:
requires:
- build
filters:
tags:
only: /^v.*/
branches:
ignore: /.*/In the example below, three jobs are defined with the build-test-deploy workflow:
-
The
buildjob runs for all branches and only tags starting with 'config-test'. -
The
testjob runs for all branches and only tags starting with 'config-test'. -
The
deployjob runs for no branches and only tags starting with 'config-test'.
workflows:
build-test-deploy:
jobs:
- build:
filters: # required since `test` has tag filters AND requires `build`
tags:
only: /^config-test.*/
- test:
requires:
- build
filters: # required since `deploy` has tag filters AND requires `test`
tags:
only: /^config-test.*/
- deploy:
requires:
- test
filters:
tags:
only: /^config-test.*/
branches:
ignore: /.*/In the example below, two jobs are defined (test and deploy) and three workflows utilize those jobs:
-
The
buildworkflow runs for all branches exceptmainand is not run on tags. -
The
stagingworkflow will only run on themainbranch and is not run on tags. -
The
productionworkflow runs for no branches and only for tags starting withv..
workflows:
build: # This workflow will run on all branches except 'main' and will not run on tags
jobs:
- test:
filters:
branches:
ignore: main
staging: # This workflow will only run on 'main' and will not run on tags
jobs:
- test:
filters: &filters-staging # this yaml anchor is setting these values to "filters-staging"
branches:
only: main
tags:
ignore: /.*/
- deploy:
requires:
- test
filters:
<<: *filters-staging # this is calling the previously set yaml anchor
production: # This workflow will only run on tags (specifically starting with 'v.') and will not run on branches
jobs:
- test:
filters: &filters-production # this yaml anchor is setting these values to "filters-production"
branches:
ignore: /.*/
tags:
only: /^v.*/
- deploy:
requires:
- test
filters:
<<: *filters-production # this is calling the previously set yaml anchor| Webhook payloads are capped at 25 MB and for some events a maximum of 3 tags. If you push several tags at once, CircleCI may not receive all of them. |
Using regular expressions to filter tags and branches
CircleCI branch and tag filters support the Java variant of regex pattern matching. When writing filters, CircleCI matches exact regular expressions.
For example, only: /^config-test/ only matches the config-test tag. To match all tags starting with config-test, use only: /^config-test.*/ instead.
Using tags for semantic versioning is a common use case. To match patch versions 3-7 of a 2.1 release, you could write /^version-2\.1\.[3-7]/.
For full details on pattern-matching rules, see the java.util.regex documentation.
Using workspaces to share data between jobs
Each workflow has an associated workspace which can be used to transfer files to downstream jobs as the workflow progresses. For further information on workspaces and their configuration see the Using Workspaces to Share Data Between Jobs doc.
Rerunning a workflow’s failed jobs
When you use workflows, you increase your ability to rapidly respond to failures. To rerun only a workflow’s failed jobs, click the Workflows icon in the app and select a workflow to see the status of each job, then click the Rerun button and select Rerun from failed.
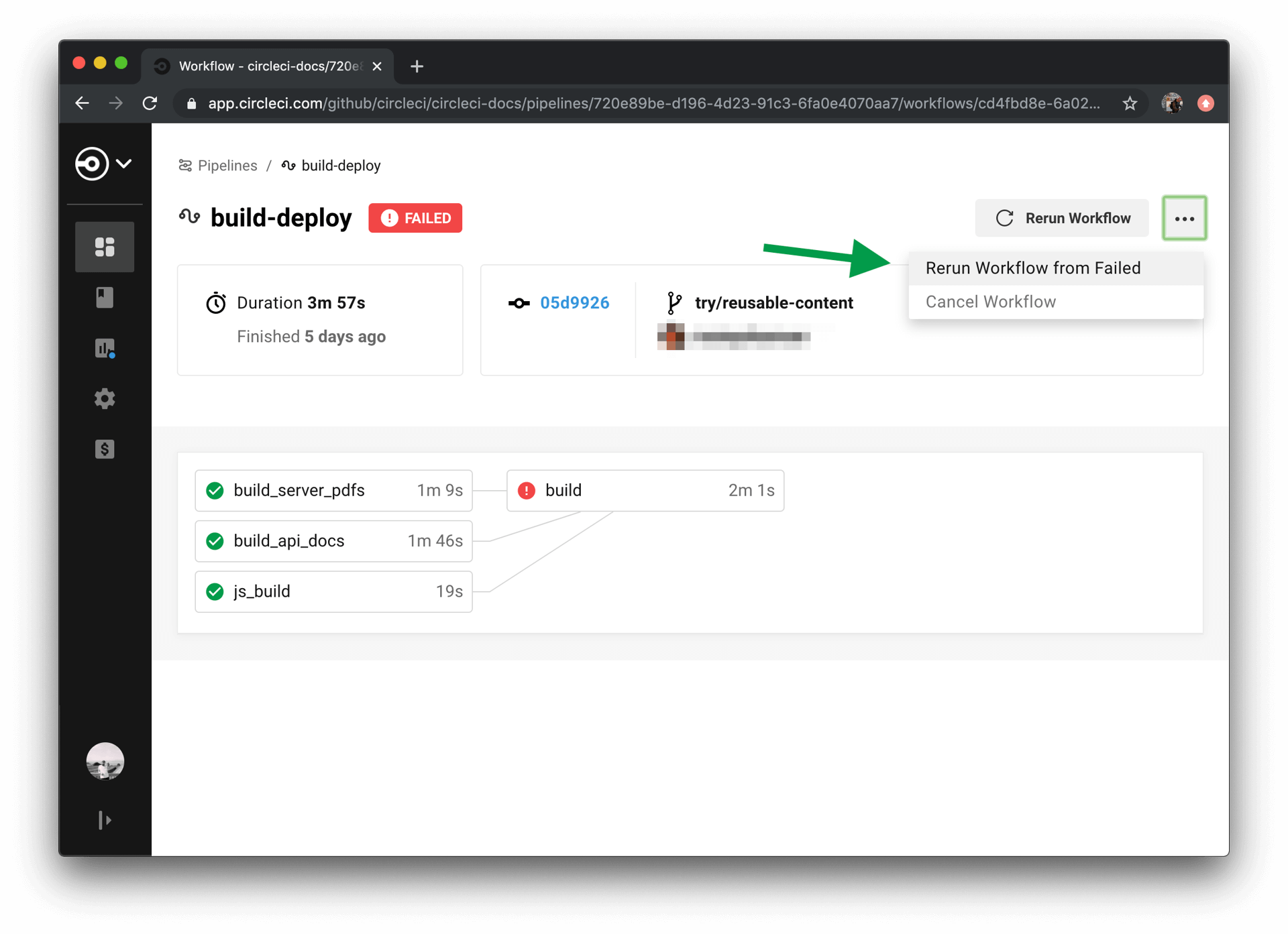
| If you rerun a workflow that contains a job which was previously re-run with SSH, the new workflow will be run with SSH enabled for that job, even after SSH capability has been disabled at the project level. |
Troubleshooting
This section describes common problems and solutions for workflows.
Workflow and subsequent jobs do not trigger
If you do not see your workflows triggering, a common cause is a configuration error preventing the workflow from starting. As a result, the workflow does not start any jobs. Navigate to your project’s pipelines and click on your workflow name to discern what might be failing.
Rerunning workflows fails
In some cases, a failure may happen before the workflow runs (during pipeline processing). Re-running the workflow will fail even though it was succeeding before the outage. To work around this, push a change to the project’s repository. This will re-run pipeline processing first, and then run the workflow.
| You cannot re-run jobs and workflows that are 90 days or older. |
Workflows waiting for status in GitHub
If you have implemented Workflows on a branch in your GitHub repository, but the status check never completes, there may be status settings in GitHub that you need to deselect. For example, if you choose to protect your branches, you may need to deselect the ci/circleci status key as this check refers to the default CircleCI 1.0 check, as follows:
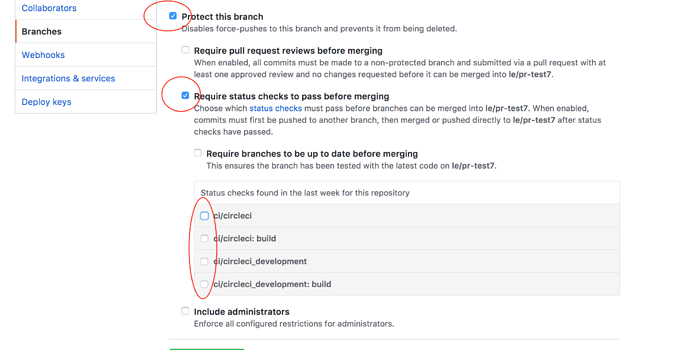
Having the ci/circleci checkbox enabled will prevent the status from showing as completed in GitHub when using a workflow because CircleCI posts statuses to GitHub with a key that includes the job by name.
Go to in GitHub and click Edit on the protected branch to deselect the settings, for example: https://github.com/your-org/project/settings/branches.
See also
-
For frequently asked questions and answers about workflows, see the workflows section of the FAQ.
-
For demo apps configured with workflows, see the CircleCI Demo Workflows page on GitHub.