By now, almost everyone is familiar with cloud computing in one form or another. Throughout the 2010s, the concept of cloud computing evolved within the software industry, then worked its way into everyday life as a universal household term.
Somewhat less familiar is the concept of edge computing. The genesis of the “edge” dates to the first content delivery networks in the 1990s. Since then, the edge concept has primarily been the domain of network engineers. Edge computing has recently come into its own, skyrocketing in popularity to become a significant concept in a new world of distributed computing.
What is edge computing?
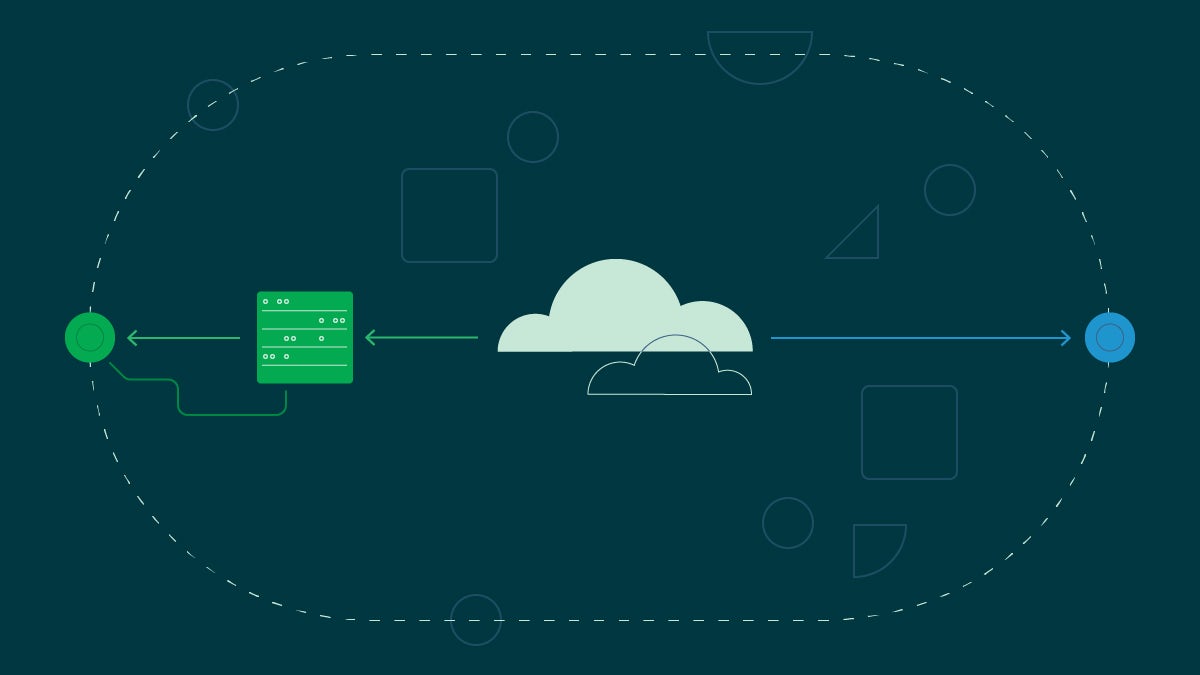
The concept of the edge is all about physical distance. The edge minimizes latency and increases performance by eliminating as much round-trip time as possible. Edge computing achieves this by directing network connections to the nearest edge computing node relative to the end user’s physical location.
Fundamentally, this is the same concept as a content delivery network (CDN). But where a CDN’s primary goal is to accelerate the transmission of static assets like images and videos, edge computing focuses on processing code on hardware assets that are as close to the end-user as possible.
Edge computing can offer a substantial performance increase for demanding applications requiring speed and performance. Because edge computing nodes are much more numerous and widely distributed than servers or data centers, applications that take advantage of edge computing can offer minimal latency to users worldwide. Such applications also provide the opportunity to concentrate edge nodes in a specific service location for unparalleled performance.
Edge computing nodes take the form of virtual machines (VMs) and containers running on strategically-positioned servers chosen for their proximity to concentrations of end users. Popular edge computing provider StackPath takes this approach.
Another method relies on a serverless methodology to execute specific code without a dedicated server. One example of this, Cloudflare Functions, allows code to run at different locations on the Cloudflare network without requiring a dedicated server.
Differences between edge computing and cloud computing
Even though we’ve defined edge computing here, there is still some overlap between edge and cloud computing concepts. Both ideas involve using remote distributed computing resources to perform tasks and execute code. In this sense, edge computing can be considered a subset of cloud computing, but with a few key differences.
Inherent to the concept of the edge is speed and performance. While the cloud is a multi-tool, offering a wide variety of services and options, edge computing has a much narrower focus. It prioritizes minimizing latency in favor of maximizing performance.
Edge computing’s infrastructure reflects this difference. While cloud and edge computing both rely on networks of distributed servers, edge computing infrastructure requires a more significant number of points of presence (POPs), with those POPs equipped with far more capable hardware than a typical cloud server. Edge POPs require advanced infrastructure capable of handling the computing load for various performance-sensitive edge applications.
Though there are critical differences between the two, the concepts of edge and cloud computing do not oppose one another. Used together, they can optimize performance in enterprise applications. High-performance and latency-sensitive tasks take place on edge POPs while less-demanding work happens elsewhere in the cloud.
Edge computing use cases
Because edge computing improves performance by minimizing latency, use cases tend to be highly-demanding applications or applications where most end-users live in a specific geographic location.
Perhaps the best example of an edge computing use case is multiplayer gaming. Modern video games are often highly demanding and resource-intensive software, both for the player’s machine and the servers that facilitate online play. Latencies must be minimal to create a consistent player experience. Because multiplayer games often connect players from extremely diverse geographical locations, edge POPs are an ideal solution for eliminating lag and creating a smooth experience.
Other use cases for edge computing are less concerned with extreme hardware performance and instead provide improvements purely through geographic proximity. Services such as ridesharing or restaurant delivery apps tend to have a focused and consistent end-user service area. Although these services may not be particularly demanding individually, the overall quality and performance of the service can dramatically improve by ensuring these apps are running code on edge POPs within a short distance of the end user.
Extending CI/CD for edge projects
From the perspective of continuous integration and continuous deployment (CI/CD), there is little difference between the cloud and the edge. To create edge POPs, service providers cleverly position hardware deployments near the service recipient. Users can update and maintain them using the same tools that enable CI/CD within the cloud or for on-premise environments.
One significant difference between the cloud and the edge is the sheer amount of hardware. Edge POPs must be far more numerous than simple cloud servers or data centers. For this reason, edge computing is an ideal use case for CI/CD. The automation provided in a CI/CD pipeline significantly reduces the workload necessary to deploy new code to edge POPs, which might otherwise require someone to manually update dozens or even hundreds of environments.
Moving to the edge
For software that needs the kind of performance that just cannot tolerate extra latency, or for applications operating in a highly-localized service area, edge computing offers substantial benefits that traditional cloud services lack.
With the proper tooling in place (such as a consistently-flowing CI/CD pipeline), the route to moving services to the edge can look like deploying anywhere else. The primary concern is in the architecture, where only appropriate code and services should move to edge POPs. Less-demanding services can often remain in the cloud, with edge POPs handling the heavy lifting while communicating with other cloud or on-premises resources.
A proper edge deployment is invisible to the end users. With the appropriate methodology, the edge can be just a footnote for the organization and DevOps teams responsible for the deployment. As networks grow ever larger and software becomes more interconnected, we are likely to see the number of available edge POPs continue to grow. Reliance on edge services will become a more commonplace deployment strategy.
It is not a case of cloud computing and edge computing fighting for supremacy. Instead, think of the edge as a natural extension of the cloud.
To learn more about optimizing deployment to cloud and edge environments using a CI/CD pipeline, sign up for a free CircleCI account and start building today.