Persisting Data Overview
On This Page
- Caching
- Caching dependencies
- Caching optimization
- Workspaces
- Workspace optimization
- Artifacts
- Artifact optimization
- Managing network and storage usage
- Overview of all network and storage transfer
- Custom storage usage
- How to calculate an approximation of network and storage costs
- Reducing excess use of network egress and storage
- See also
This guide gives an introductory overview of the various ways to persist and optimize data within and beyond your CircleCI builds. There are a number of ways to move data into, out of, and between jobs, persisting data for future use. Using the right feature for the right task will help speed up your builds, and improve repeatability and efficiency.
Note the following distinctions between artifacts, workspaces, and caches:
| Type | Use | Example |
|---|---|---|
| Artifacts | Preserve long-term artifacts. | Available in the Artifacts tab of the Job page under the tmp/circle-artifacts.<hash>/container or similar directory. |
| Workspaces | Attach the workspace in a downstream container with the attach_workspace: step. | The attach_workspace copies and re-creates the entire workspace content when it runs. |
| Caches | Store non-vital data that may help the job run faster, for example npm or Gem packages. | The save_cache job step with a path to a list of directories to add and a key to uniquely identify the cache (for example, the branch, build number, or revision). Restore the cache with restore_cache and the appropriate key. |
Caching
Caching persists data between the same job in different workflows, allowing you to reuse the data from expensive fetch operations from previous jobs. After an initial job run, future pipelines will run faster as they will not need to redo the work (provided your cache has not been invalidated).
Caching dependencies
A prime example of a caching strategy is using a cache with dependency managers, such as Yarn, Bundler, or Pip. When dependencies are restored from a cache, commands like yarn install will only need to download new dependencies (if any), instead of re-downloading every dependency on every build.
Because caches are global within a project, a cache saved on one branch will be used by jobs run on other branches. Caches should only be used for data that is suitable to share across branches.
- For more information on caching dependencies, including race conditions, managing caches, and using cache keys, see the Caching Dependencies page.
Caching optimization
There are several common ways that your configuration can be optimized to ensure you are getting the most out of your network and storage usage. For example, when looking for opportunities to reduce data usage, consider whether specific usage is providing enough value to be kept. In the case of caches, this can be quite easy to compare. Does the developer or compute time-saving from the cache outweigh the cost of the download and upload?
Caching optimization strategies can include avoiding unnecessary workflow reruns, combining jobs, creating meaningful workflow orders, and pruning.
- For more information on caching optimization and other caching strategies, like partial dependency caching, caching tradeoffs, and using multiple caches, see the Caching Strategies page.
Workspaces
Workspaces are used to transfer data to downstream jobs as the workflow progresses. When a workspace is declared in a job, files and directories can be added to it. Each addition creates a new layer in the workspace filesystem. Downstream jobs can then use this workspace for their own needs, or add more layers on top.
Workspace optimization
If you notice your workspace usage is high and would like to reduce it, try searching for the persist_to_workspace command in your .circleci/config.yml file to find all jobs utilizing workspaces and determine if all items in the path are necessary.
You also might find that you are only using workspaces to be able to re-run builds from fail. Once the failing build passes, the workspace might not be needed. Setting a low storage period of, for example, one day, might be suitable for your projects. A low storage retention period for workspaces will save costs by not keeping unnecessary data in storage.
- For more information on workspace optimization, configuration, and expiration, see the Using Workspaces page.
- For more information on workflows, see the Workflows page.
- Also see the Deep Diving into CircleCI Workspaces blog post.
Artifacts
Artifacts are used for longer-term storage of the outputs of your pipelines. For example, if you have a Java project, your build will most likely produce a .jar file of your code. This code will be validated by your tests. If the whole build/test process passes, then the output of the process (the .jar) can be stored as an artifact. The .jar file is available to download from our artifacts system long after the workflow that created it has finished.
If your project needs to be packaged, say an Android app where the .apk file is uploaded to Google Play, you would likely wish to store it as an artifact. Many users take their artifacts and upload them to a company-wide storage location such as Amazon S3 or Artifactory.
Artifact optimization
Artifacts can be useful for troubleshooting why a pipeline is failing. However, once the issue is resolved and the pipeline runs successfully, the artifact might serve little purpose. Setting a storage period of, for example, one day, allows you to both troubleshoot the build as well as save costs by not keeping unnecessary data in storage.
If you need to store artifacts for longer periods of time, there are other optimization options available, depending on what you are trying to accomplish. Every project is different, but you can try the following actions to reduce network and storage usage:
- Check if
store_artifactsis uploading unnecessary files - Check for identical artifacts if you are using parallelism
- Compress text artifacts at minimal cost
- Filter out and upload only failing UI tests with images/videos
- Filter out and upload only failures or successes
- Upload artifacts to a single branch
- Upload large artifacts to your own bucket at no cost
For more information on artifact optimization, and using artifacts to persist data once a job has completed, see the Storing Build Artifacts page.
Managing network and storage usage
Optimization goes beyond speeding up your builds and improving efficiency. Optimization can also help reduce costs. The information below describes how your network and storage usage is accumulating, and should help you find ways to optimize and implement cost saving measures.
To view your network and storage usage, visit the CircleCI web app and follow these steps:
- Select Plan from the app sidebar.
- Select Plan Usage.
- Select the Network or Storage tab depending on which you want to view.
On the Network and Storage tabs, you will find a breakdown of your usage for the billing period. The usage is also broken down by storage object type: cache, artifact, and workspace.
If you find you have more questions about your network and storage usage beyond what you can see on the CircleCI web app, please contact support by opening a ticket for Accounts / Billing.
Overview of all network and storage transfer
All data persistence operations within a job will accrue storage usage, though not all storage usage will result in costs. The relevant actions for accruing storage usage are:
- Uploading caches
- Uploading workspaces
- Uploading artifacts
To determine which jobs utilize the above actions, you can search for the following commands in your project’s .circleci/config.yml file:
save_cachepersist_to_workspacestore_artifacts
Details about your network and storage transfer usage can be viewed on your Plan > Plan Usage screen. On this screen you can find:
- Billable Network Transfer & Egress (table at the top of the screen)
- Network and storage usage for individual projects (Projects tab)
- Storage data activity (Network tab)
- Total storage volume data (Storage tab)
The only network traffic that will result in billing is accrued through restoring caches and workspaces to self-hosted runners. Retention of artifact, workspace, and cache objects will result in billing for storage usage.
Details about individual network and storage transfer usage can be found in the step output on the Jobs page as seen below.
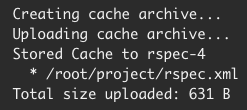
Custom storage usage
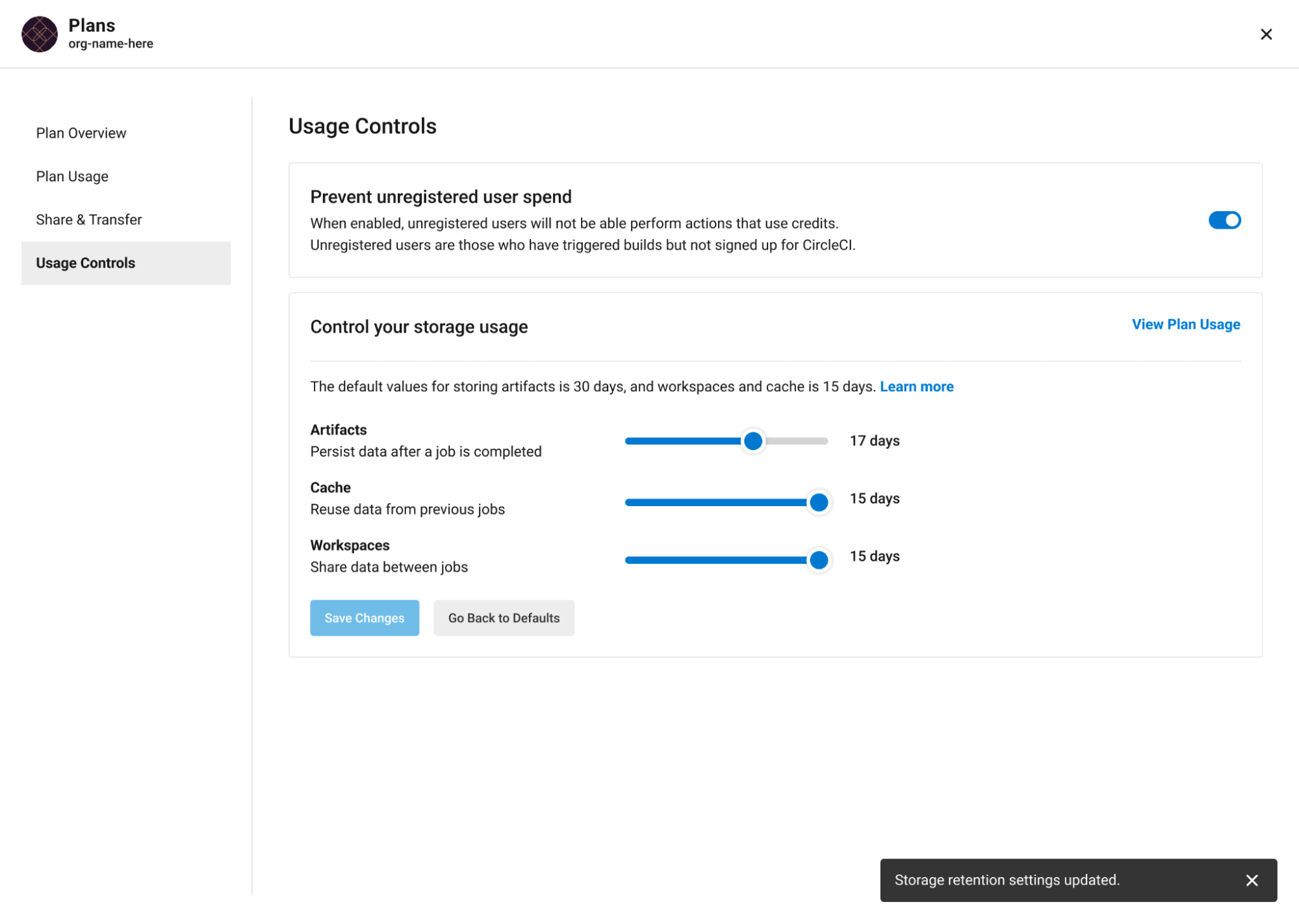
Users on paid plans can customize storage usage retention periods for workspaces, caches, and artifacts on the CircleCI web app by navigating to Plan > Usage Controls. Here you can set custom storage periods by adjusting the sliders for each object type (see image below). By default, the storage period is 30 days for artifacts, and 15 days for caches and workspaces. These are also the maximum retention periods for storage. The maximum storage period is 30 days for artifacts, and 15 days for caches and workspaces.
When you have determined your preferred storage retention for each object type, click the Save Changes button and your preferences will take effect immediately for any new workspaces, caches, or artifacts created. Previously created objects that are stored with a different retention period will continue to persist for the retention period set when the object was created.
The Reset to Default Values button will reset the object types to their default storage retention periods: 30 days for artifacts, and 15 days for caches and workspaces.
Anyone in the organization can view the custom usage controls, but you must be an admin to make changes to the storage periods.
If you store data toward the end of your billing cycle, the data will be restored when the cycle restarts, for whatever storage period you have set in your usage controls. For example, if you restore and save a cache on day 25 of your billing cycle with a 10 day storage period set, and on day 30 no changes have been made to the cache, on day 31, a new cache will be built and saved for a new 10 day storage period.
How to calculate an approximation of network and storage costs
Network charges apply when an organization has runner network egress beyond the included network GB allotment. Billing for network usage is only applicable to traffic from CircleCI to self-hosted runners. If you are exclusively using our cloud-hosted executors, no network fees apply.
Storage charges apply when you retain artifacts, workspaces, and caches beyond the included storage GB allotment.
You can find out how much network and storage usage is available on your plan by visiting the features section of the Pricing page. If you would like more details about credit usage, and how to calculate your potential network and storage costs, visit the billing section on the FAQ page.
For questions on data usage for the IP ranges feature, visit the FAQ page.
Reducing excess use of network egress and storage
Usage of network transfer to self-hosted runners can be mitigated by using custom local storage, such as a persistent volume as opposed to the built-in caches/workspaces provided by CircleCI.
Billing for storage can be minimized by evaluating your storage needs and setting custom storage retention periods for artifacts, workspaces, and caches on the CircleCI web app by navigating to Plan > Usage Controls.