Nomad クラスタの操作ガイド
CircleCI では、プライマリジョブスケジューラとして Nomad を使用します。 ここでは、CircleCI Server で Nomad クラスタを操作する方法をご理解いただくための Nomad の基本的な概要について説明します。
基本的な用語とアーキテクチャ
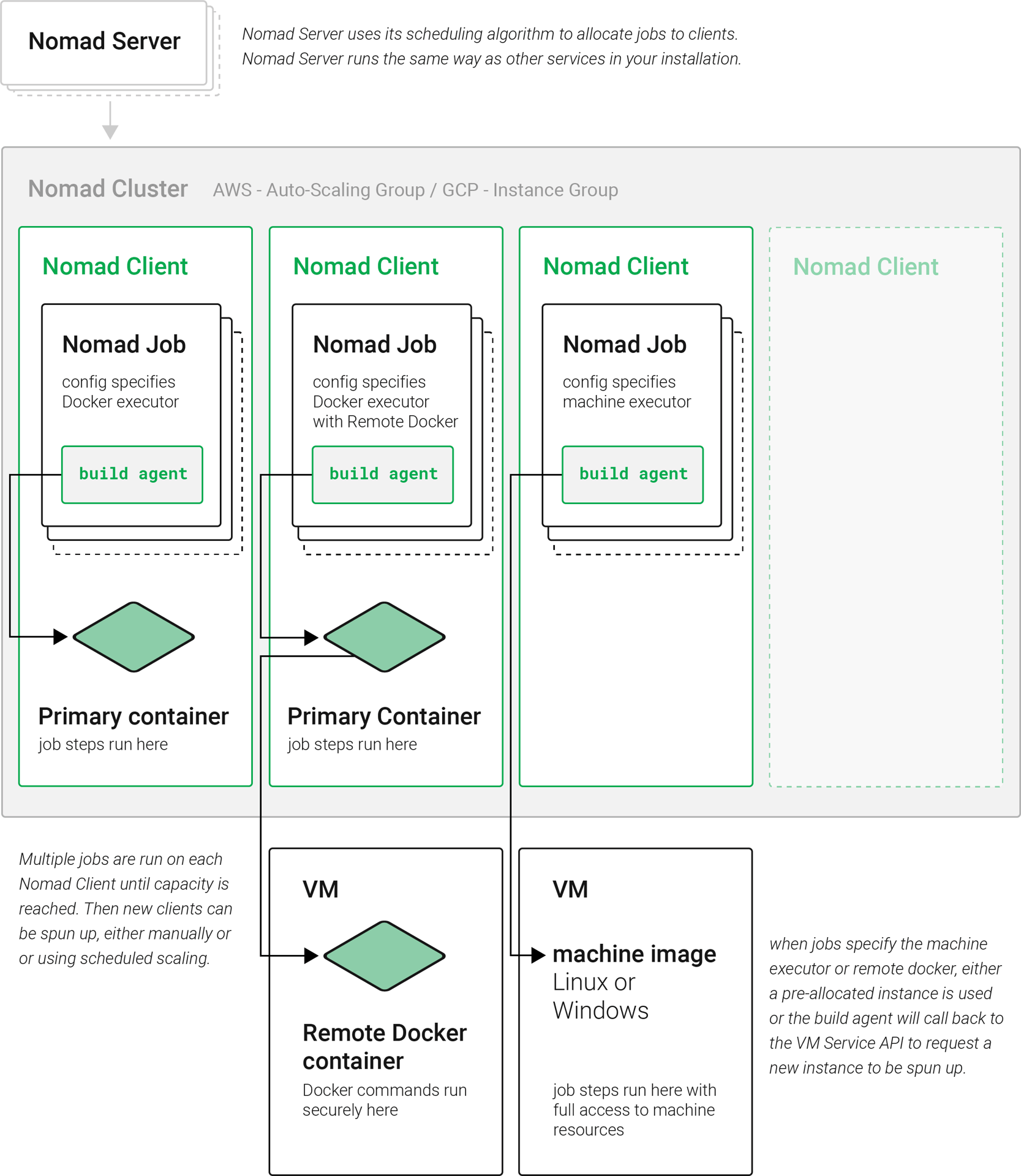
-
Nomad サーバー: Nomad サーバーは、Nomad クラスタの「頭脳」です。 ジョブを受け取り、Nomad クライアントに割り当てます。 CircleCI Server では、Nomad サーバーは Kubernetes クラスタ内でサービスとして実行されます。
-
Nomad クライアント: Nomad クライアントは、Nomad サーバーによって割り当てられたジョブを実行します。 通常、Nomad クライアントは専用のマシン (多くの場合は VM) 上で実行されるため、マシンの能力を最大限に活用できます。 複数の Nomad クライアントで 1つのクラスタを構成することができ、Nomad サーバーはスケジュールアルゴリズムに従ってクラスタにジョブを割り当てます。
-
Nomad ジョブ: Nomad ジョブは、Nomad のワークロードを宣言するユーザーによる仕様です。 Nomad ジョブは、CircleCI ジョブの実行に対応しています。 ジョブで 並列実行 を使用する場合、例えば
parallelism: 10の場合、Nomad は 10 個のジョブを実行します。 -
ビルドエージェント: ビルドエージェントは、CircleCI 製の Go プログラムです。ジョブ内のステップを実行し、結果を報告します。 ビルドエージェントは、Nomad ジョブ内でメインプロセスとして実行されます。
基本的な操作
ここでは、CircleCI での Nomad クラスタの基本的な操作について説明します。
Nomad Pod には nomad CLI がインストールされています。 Nomad クラスタとやり取りするようにあらかじめ設定されているため、kubectl と nomad コマンドを使用して、以下で説明するコマンドを実行することができます。
ジョブステータスの確認
クラスタ内のすべてのジョブのステータス一覧を表示するには、以下のコマンドを実行します。
kubectl exec -it <nomad-server-pod-ID> -- nomad statusStatus は、出力内容のうち最も重要なフィールドで、以下のステータスが表示されます。
-
running: Nomad でジョブの実行が開始されています。 通常、CircleCI 内のジョブが開始されていることを意味します。 -
pending: クラスタ内でジョブを実行するためのリソースが不足している状態です。 -
dead: Nomad によるジョブの実行が終了しています。 対応する CircleCI ジョブまたはビルドが成功したか失敗したかにかかわらず、ステータスは dead になります。
クラスタステータスの確認
Nomad クライアントのリストを取得するには、以下のコマンドを実行します。
kubectl exec -it <nomad-server-pod-ID> -- nomad node-statusnomad node-status コマンドを実行すると、現在稼働中の Nomad クライアント (ステータスが active) と、クラスタから除外された Nomad クライアント (ステータスが down) の両方が報告されます。 そのため、現在のクラスタの容量を知るには、ステータスが active な Nomad クライアントの数を数える必要があります。 |
特定のクライアントの詳細情報を表示するには、そのクライアントで以下のコマンドを実行します。
kubectl exec -it <nomad-server-pod-ID> -- nomad node-status -selfこれにより、クライアント上で実行中のジョブの数や、クライアントのリソースの利用状況などの情報が表示されます。
ログの確認
Nomad ジョブは、CircleCI ジョブの実行に対応しています。 そのため、CircleCI ジョブで問題が発生した場合、Nomad ジョブのログを確認すると、そのジョブのステータスを理解するのに役立つことがあります。 特定のジョブのログを取得するには、以下のコマンドを実行します。
kubectl exec -it <nomad-server-pod-ID> -- nomad logs -job -stderr <nomad-job-id>-stderr フラグは必ず指定してください。 これにより、ほとんどのビルドエージェントのログが表示されます。 |
nomad logs -job コマンドは便利ですが、-job フラグは指定されたジョブのランダム割り当てを使用するため、必ずしも正確とは限りません。 allocation は Nomad ジョブ内のさらに小さい単位で、このドキュメントでは取り上げていません。 詳細については、 公式ドキュメント を参照してください。
指定したジョブの割り当て(allocation)からログを取得するには、以下の手順を行います。
-
nomad statusコマンドで、ジョブ ID を取得します。 -
nomad status <job-id>コマンドで、ジョブの割り当て ID を取得します。 -
nomad logs -stderr <allocation-id>で、割り当てからログを取得します。
Nomad クライアントのシャットダウン
Nomad クライアントをシャットダウンするときは、まずクライアントを drain モードに設定する必要があります。 drain モードのクライアントでは、それまでに割り当てられたジョブは完了しますが、新たにジョブを割り当てることはできません。
-
クライアントをドレインするには、クライアントにログインし、
node-drainコマンドを以下のように使用して、クライアントをドレインモードに設定します。nomad node-drain -self -enable -
次に、
node-statusコマンドを使用してクライアントがドレインモードに変更されていることを確認します。nomad node-status -self
また、下記のコマンドにノード ID を代入して実行し、リモートノードをドレインモードに設定することもできます。
nomad node-drain -enable -yes <node-id>クライアントクラスタのスケールダウン
クライアントをシャットダウンするメカニズムを設定するには、まずクライアントを drain モードに変更し、すべてのジョブが完了してから、クライアントを終了させます。 ASG ライフサイクルフック を設定することで、インスタンスをスケールダウンするスクリプトをトリガーできます。
このスクリプトで、上述のコマンドを使用して以下の手順を実行します。
-
インスタンスをドレインモードに設定します。
-
インスタンスで実行中のジョブを確認し、ジョブが完了するのを待ちます。
-
インスタンスを終了します。
次のステップ
-
ユーザーアカウントの管理 ガイドをお読みください。