We built workflows to free teams to run their builds in any way they choose. Workflows enable enormous customization, but there are also many decisions to be made: Should you opt for sequential or parallel jobs? How should you handle testing across multiple languages? And should you set up any automatic actions if a test fails?
We wanted to showcase some of the many things workflows can do for you. But instead of just telling you how you could set your configuration up, we wanted to show you how real development teams are using workflows right now to ship applications. So we combed through many of the projects using CircleCI 2.0 in their open source repos in order to give you access to the real config files these teams are using. If you see something that could be useful for your team, you’ll know exactly how it was set up.
We’ve split these examples into three types of tasks, with one bonus post:
- Job orchestration (this post)
- Multi-executor
- Control
- How we use workflows at CircleCI
Over the next four blog posts, we’ll be walking you through the various configurations of workflows and the reasons teams are using them.
Workflows basics
For those who are new to workflows, let’s define some key terms:
- WORKFLOWS A set of rules defining how jobs (such as build, test, deploy) are run, giving teams granular control over their software development process
- JOBS A collection of steps and an execution environment to run them in
- STEP An executable command
Alright, let’s check out some workflows!
Open-source examples
The first concept we want to explore is job orchestration, or, setting up your jobs to run either sequentially or in parallel. There are good reasons to do both, so let’s explore some examples.
Example 1: Artsy
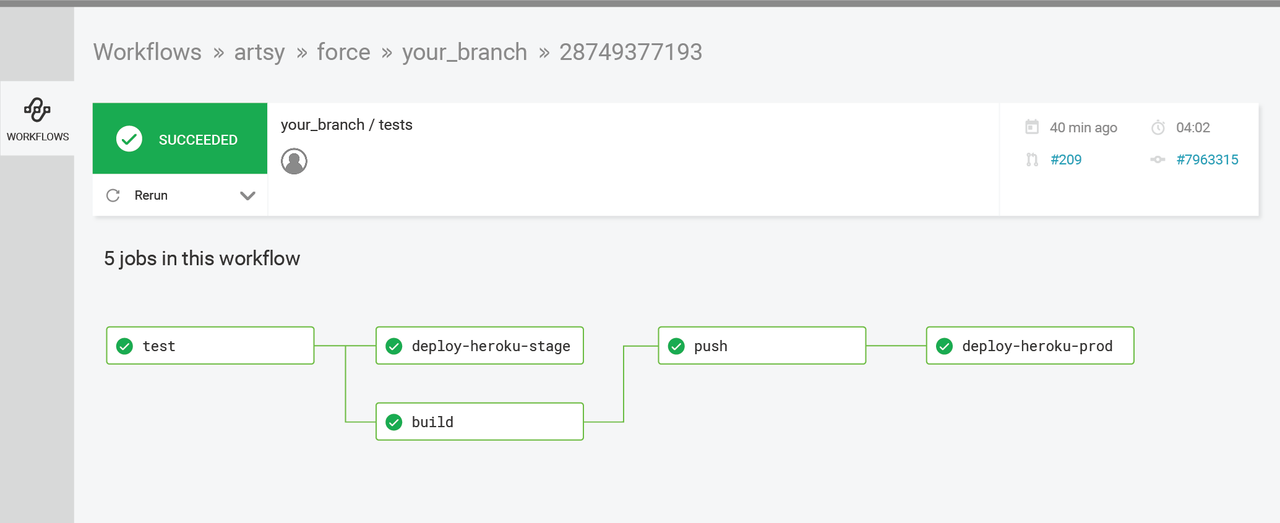 See Artsy’s config.yml here.
See Artsy’s config.yml here.
This is an example of sequential workflow (though not purely sequential - they run their deploy_heroku and build jobs in parallel). Their workflow contains a simple build-test-deploy sequence wherein they deploy to staging before deploying to production. If you are interested in running your test(s) before building and deploying, or doing sequential deploys to staging and production, this is a great example of what that would look like. One benefit of running sequentially is that if you spot an issue when you deploy to staging, you can resolve that issue before going any further. Using sequential jobs, you get incremental feedback and can make changes at any stage.
Example 2: Mapbox
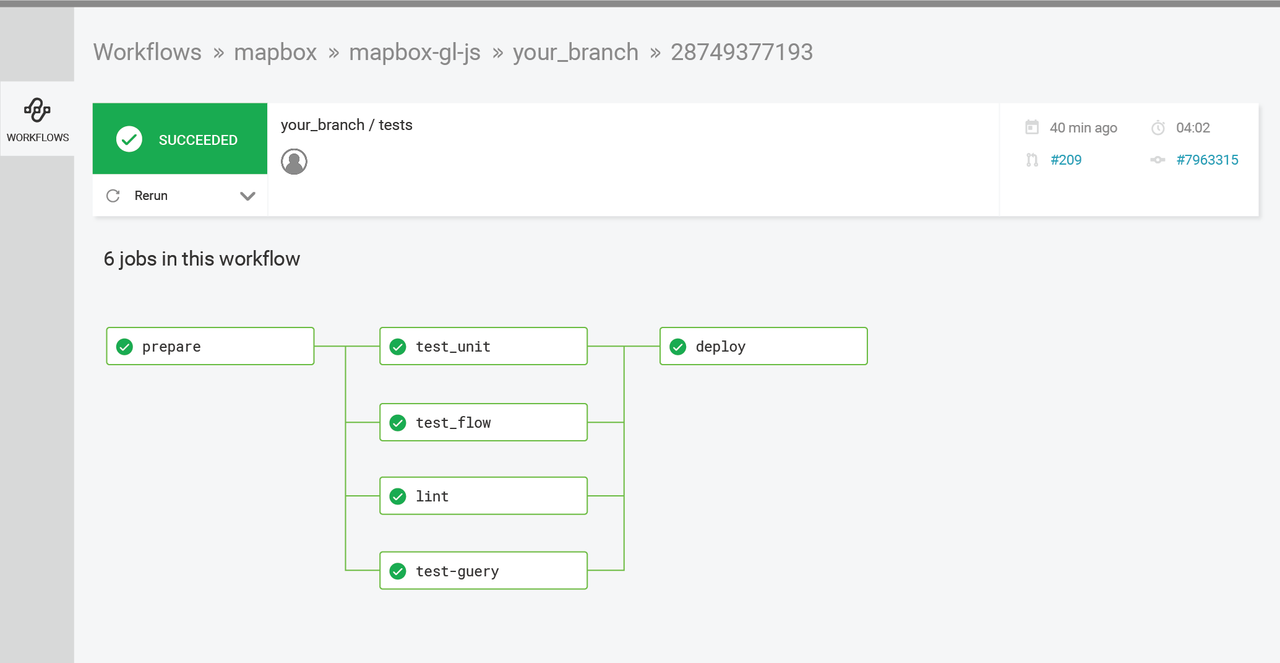 See Mapbox’s config.yml here.
See Mapbox’s config.yml here.
In this example, Mapbox is running tests across multiple jobs to get faster feedback. They are running integration tests, unit tests, and code lint tests at the same time to get feedback across their different test suites before they merge to master and deploy. This would be recommended to teams who want to optimize the total run time of their test suites by running all your tests from a single push. This is a great option for most teams.
Some additional notes:
If you’ve heard of the terms fan-in and fan-out, we’ve already covered what they do! In Mapbox’s example, they start their workflow with the prepare job, then fan out into their test suite which runs in parallel, then they fan back in to the deploy job.
What if my tests fail?
Regardless of whether you choose to run in parallel or sequentially, what do you do if you encounter a problem where one or more of your jobs fails?
There are a few options:
- Re-run from the beginning: You can re-run your workflow from the beginning using the same commit to trigger a new workflow.
- Re-run from failed: If you think that you have a flaky test, or you have a job that didn’t deploy properly, you don’t have to re-run the whole workflow. Instead, just start from the jobs that failed.
Use job orchestration options to achieve faster feedback on what’s working and what’s failing so you can make changes quickly and keep on shipping. Next in our blog series is a look into open source projects using multi-executor workflows.