AI adoption for software: a guide to learning, tool selection, and delivery

Chief Technology Officer

This post was written with valuable contributions from Michael Webster, Kira Muhlbauer, Tim Cheung, and Ryan Hamilton.
Remember the advent of the internet in the 90s? Mobile in the 2010s? Both seemed overhyped at the start, yet in each case, fast-moving, smart teams were able to take these new technologies at their nascent stage and experiment to transform their businesses.
This is the moment we’re in with artificial intelligence. The technology is here. If you’re not testing the waters with AI, your competitors surely are.
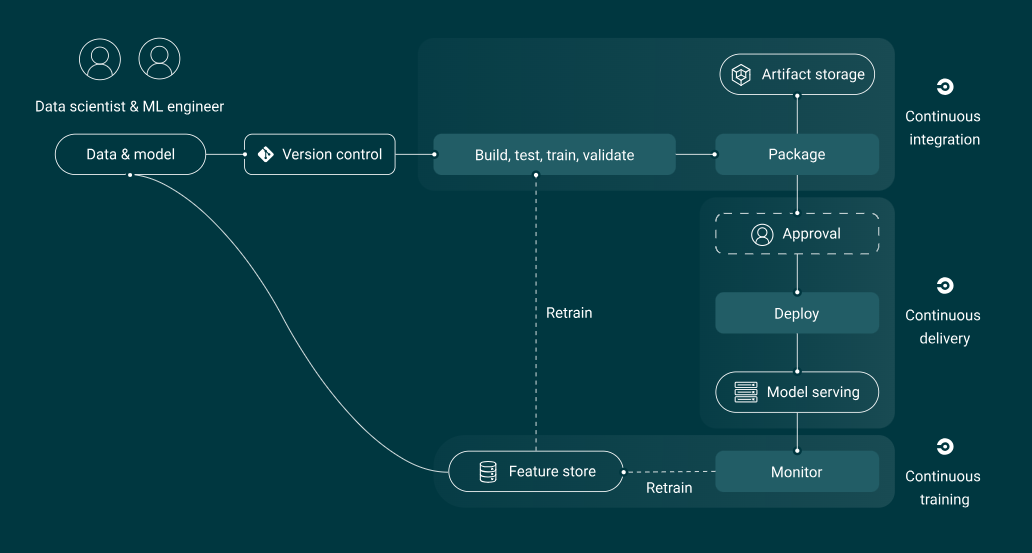
For the last six months, a tiger team of engineers has been exploring how we can apply AI to our work at CircleCI, and along the way we’ve developed a phased approach to exploration that we think may be helpful to others just beginning to navigate this space. What follows is a conceptual guide to going from brainstorming to production on incorporating AI into your application. For a tech-forward tutorial, you can read more on CI for machine learning and CD for machine learning, as well as a deeper understanding of the challenges of ML model development.
So how do you get from feeling the pressure to utilize AI but not knowing where to start, to shipping AI features into production? Read on.
1. Identify business objectives
Before you start trying out tools like ChatGPT, decide what you want to achieve with AI.
When our team was beginning to explore how we could leverage AI in our business, we conducted a series of open-ended interviews with all our Product Managers to get an idea of where we might apply AI to help solve problems.
We asked questions like:
- “What kind of problems are you having right now that you don’t have a solution for yet?”
- “What have users complained about”?
We specifically instructed our interviewees not to think about their answers with AI in mind, as we didn’t want them to accidentally leave out something that could be valuable. For CircleCI, this helped us immensely by giving us a direction to focus our explorations in, knowing we would be applying the power of AI to solve our company’s most pressing issues.
If you’re just getting started thinking about business objectives to which you could apply AI, here are some thought starters:
- Generate a list of current problems and ask yourself, or your team: “what if these were easy and you could ask a computer to solve them for you?”
- Look for places to apply AI to internal problems. There is so much text in every organization and LLMs are good at summarizing and generating text. You may not generate the next great American novel, but AI can help you craft an email in a professional tone.
- Try automating things your customers have to do by hand today. For example, if there is text they have to read, there’s a good chance an LLM can help them understand it faster.
Remember, LLMs are astoundingly good at some types of work, and not that good at others. In our experience, LLMs are really good at:
- Summarizing information
- Translating something technical (code, an error message, logs) into natural language that’s easier to understand, translating one language into another
- Sentiment analysis
- Tasks that are open-ended or creative
They are mediocre at:
- Translating natural language into code (often creating mistakes that humans need to fix)
- Answering questions (recall that GPT doesn’t have knowledge about anything after 2021)
- Technical tasks that require a precise correct answer, such as math problems
To progress from this stage, you don’t need an exact plan for how you want to apply AI, but rather a loose roadmap of some areas you think might be fruitful for further exploration.
2. Analyze your best opportunities
Now, with the feedback you received in your interviews in mind, it’s time to evaluate what your organization is working with as you decide where you may be able to incorporate AI technology effectively.
Some good questions to ask are:
- “Who are we as an organization?”
- “What do we value?”
- “What are our strengths? Weaknesses?”
- “What are our top priorities?”
- “How could we likely leverage AI to enhance the above?”
In answering these questions, you may, as we did, find no shortage of ideas, but prioritizing them is key.
Your ideas will likely range in terms of complexity, size of time and/or financial investment, and potential reward.
Consider which investment may bring the largest or most immediate return.
| Investment Level | Potential Reward | Action |
|---|---|---|
| Small | Major | Start working on it ASAP |
| Small | Minor | Deprioritize it in favor of larger returns |
| Sizable | Major | Keep an eye on it, balance it against future priorities |
| Sizable | Minor | Remove it from your list |
3. Determine and train team for AI expertise
Once you’ve ascertained not just the most viable ideas, assess your technical readiness as a team.
While it makes sense to consider factors like technical capabilities, infrastructure, data availability, storage, processing power, and other tangible assets in your assessment, we suggest a more holistic way of looking at the problem.
Generally, any company is going to have some level of technical capability, infrastructure, and actual data at their disposal, much like a human being is going to have abilities, strengths, weaknesses, talents, skills, and natural advantages. Where are your organization’s strengths, and how can you leverage those to apply to your AI projects? What knowledge will you need to get started on your most promising idea?
With your business goals from step 1 in mind, we suggest you first determine if one of the hundreds of available off-the-shelf model can meet those goals. If they can, then a regular software engineer will have knowledge required to hook up to your systems; you don’t need a machine learning expert.
If you think you will need to build and train your own model, then you may need to bring in someone with specific machine learning expertise.
As a concrete example, we’ve been working on ways to help CircleCI customers create configuration files more easily using AI. An existing model such as OpenAI would have a difficult time editing a CircleCI config to add advanced product features such as test splitting. The reason for this is that OpenAI’s models have been mostly trained on openly available data. Therefore the only configuration files that would be available for a model to train on would be from open-source projects, which tend to be simpler, and do not have as many instances of using our advanced features. In this case, we’d need to train our own model on a corpus of CircleCI config files.
In more general terms, if you want to have a language model summarize text in an automated fashion, that’s relatively easy. If you’re trying to fine tune the output for a specific purpose, that will require more work, more expertise, and more data.
If you find yourself assessing the potential ROI of building your own custom model instead of using an existing one, here are a few things to keep in mind:
First, consider if your organization has the data to support fine-tuning the model. If you have a use case that existing LLMs can’t handle, but you don’t have the data, fine-tuning a model is basically a non-starter.
Second, the data you use also needs to be high quality. In the context of a CircleCI application, it might mean using data only from configs that successfully compile, or which have gone through a human check.
4. Tinker, then set up a sandbox
Now it’s time to start playing! We recommend giving your team time to get comfortable working with AI models in an open-ended way. Play around without driving toward an outcome. This will help increase your team’s familiarity with both the benefits and limitations of these tools.
Ideas:
- Use ChatGPT and experiment with prompts. Ask the same question multiple times and get a sense for the variability of responses.
- Ask the model to do basic tasks like, “can you fix this code for me?” Learn the current limits by doing, instead of overthinking whether it might work or not.
- Save everything. Your interactions with models can help create demo applications and examples later on. Even if you don’t use them for products, they are easy to share and low cost to host with tools like Streamlit, Gradio, and HuggingFace spaces.
The playing around phase will come to a close when your team is able to answer a few questions about the models you’ve tried:
- How do they work?
- What are they good at?
- What are they not good at?
- How could we possibly leverage them?
- What opportunities and threats do they pose?
Then, once you’ve explored some of the edges of AI technology and considered how it may benefit your organization, it’s time to create a sandbox. This allows the team to explore and collaborate together while protecting trade secrets and ensuring private or proprietary data doesn’t get incorporated into future model training.
There are two main ways to create a sandbox:
- Use a self-hosted open source model. This gives you the best isolation, but you have to host the model somewhere and make sure it stays operational.
- Use a 3rd party model that allows you to opt-out of training. This is what we did at CircleCI. OpenAI allows opting out of training for API usage, 3rd party models tend to be better, and there are tons of ChatGPT wrappers to address this type of problem. Chatbot UI is the frontend we used, but there are many others including Hugging UI.
There are a few things we recommend keeping in mind as you and your team work inside the sandbox.
- Have fun.
- Be curious and ask questions.
- Push the AI to the limits. Once the limits are found, keep pushing on them.
- Find out what AI is good at, and what it fails at…amp up and leverage AI for the former, and use other computational tools for the latter.
- Generative AI, while impressive, is not good at everything. Sometimes doing things the old way is much better. One of our engineers says, “I’d rather use a spreadsheet or a desk calculator from the 70s for basic math than trust any LLM to do it.”
- Make sure you read the data/privacy policies of whatever model you decide to use. Even though the data you share isn’t used for training, OpenAI still has what you send them for some period of time.
- Intellectual property. LLM output is a grey area in terms of IP. OpenAI says they don’t retain copyright on data that is output from the model BUT what if the model spits out copyrighted code or books?
- Establish policies around company data before anyone gets access. What are you comfortable sending to the LLM? What is absolutely not OK to send to the LLM ever?
As part of our tinkering phase, our engineers built out two proof of concept tools: a failure summarizer (creating more readable and human-friendly error messages for CircleCI users) and self-healing pipelines (a tool that can surface issues with CI builds and then suggest and implement fixes for them).
Both of these features are now on our public product roadmap, and both emerged from open-ended tinkering. If you are willing to experiment while keeping your user and their problems in the forefront of your mind, we are confident you’ll discover interesting applications for AI in your business.
5. Tool choices
When looking at tools, first you need to decide if you’re going to:
- Utilize a 3rd party model
- Optimize an existing model
- Build your own model
One of the tools we use internally is Hugging Face, a data science and machine learning platform. They offer models for people to use in applications, datasets for people to train new models on, and application hosting called Spaces. Their libraries let you build frontends in Python very quickly, which enabled our team to rapidly stand up an internal prototype without having to deploy to our infrastructure.
Built on Hugging Face, the early version of our error summarizer looked like this:

It was very simple compared to what we are now building into the CircleCI UI, but it gave us the feedback we needed to validate the implementation. The AI space has lots of tooling to make simple internal demos easy, allowing rapid iteration on promising ideas.
Here are a few resources and tools we recommend for getting started:
- OpenAI API
- OpenAI Cookbook
- LangChain - a framework for developing applications powered by language models
- Hugging Face transformers - the go-to tool for using OSS models
- Sagemaker - AWS-based model training tool. Read our tutorial on doing ML CI/CD with Sagemaker.
Our best advice on choosing tools is to start simple, including seeing if an API can work for you. Don’t build until you actually need to.
Finally, regardless of the chosen tool, it is strongly recommended to learn Python, which has quickly become the second most popular language on our platform. Python can be learned very quickly and it’ll open up many opportunities when it comes to tool selection (again, if a tool is used at all). Sometimes tools are not needed, and most are replaceable.
6. Things to remember
Before you take the leap into production, there are a few gotchas teams experimenting with AI tools should keep in mind:
- Speed
- Cost
- Determinism
- Testing
Speed
AI inference models aren’t super fast so you want to weigh having AI calls in your pipeline to slow things down. That’s why for example our “self-healing pipeline” feature only runs when there is an error vs checking everything. This way, you only pay the latency and API token costs when you actually need it.
Cost
The GPU instances needed to run AI are expensive. In particular, deep learning and machine learning applications typically require a significant amount of computational power. Traditional CPU-based processing isn’t always sufficient or cost-effective for these operations, hence, the use of graphics processing units (GPUs).
GPUs can significantly accelerate AI workloads by handling numerous computations simultaneously. However, the cost of utilizing cloud GPU instances can quickly add up given the time-intensive nature of AI model training. Ensure your tool offers you visibility into your resource usage, as well as hybrid options for running resource-intensive builds on your own infrastructure.
Determinism
As software engineers, we are traditionally used to relatively “pure” functions and predictability in responses from them. When iterating with AI models, it has been an unique challenge to accept the variability in responses from any given AI/LLM model. For example, if you ask a calculator to calculate 5+5 one million times, it will give the same exact numeric response (10) each time, with a high level of accuracy, precision, and predictability.
Similarly, if I prompt an LMM one million times to give me the answer to 5+5, some initial answers might be: 10, 10.0, Ten, ten, TEN, “55”, dix, or “diez mi amigo!” All of the above can be considered valid (i.e. correct) under certain contextual conditions (even “55”), but there’s a ton of variability in the response set. The LLMs, even at low temperature calibrations have more variability than a 1970s desk calculator or a pure Python function.
Testing
The variability and uncertainty AI/LLMs bring to our products require a different kind of testing. Software engineers are used to writing tests that say “given X input, the output should always be Y.” Generative AI changes how we think about testing. If you give chatGPT the same exact prompt twice, you’ll likely get a similar result, but it won’t be exactly the same.
This means that you can’t write the unit tests that you’re used to writing, because there’s no single right answer. Instead, you should try to think of properties that the output should always have, and test those.
Examples:
- If the prompt is “make this text more concise”, you can test that the output is shorter than the input.
- If the prompt is “add emojis to this text”, you can test that the only additions are emojis.
Conclusion
The goal of this piece was to give you a framework for thinking through adding Generative AI capabilities to your application, including ideation, discovery, and testing. At CircleCI, we’ve seen an explosion of interest in AI/ML, from our internal R+D teams building and our customers encountering and overcoming the challenges of ML development. Looking beyond the step-by-step guide to thinking through AI in your team, it’s worth taking the 50,000 foot view to think about how software development as a whole will change in this new AI/ML paradigm.
Our mission at CircleCI is to manage change so software teams can innovate faster. When we think of traditional CI/CD, we generally think of the change we’re validating as one that a human initiated: developer makes change in code, in the form of a pull request. While most applications today are made up of more than just your repository — think 3rd party services, open source libraries, packages, not to mention microservices death stars — generative AI introduces changes to an application at a rate our industry has never seen before.
How will our industry evolve to keep up? What does the software delivery lifecycle look like with GenAI riding shotgun in your application’s development and iteration? Does the basic CI/CD workflow of Build > Test > Deploy evolve into Build > Train > Test > Package > Deploy > Monitor? Who is responsible for maintaining and supporting AI-generated code in production, nevermind ensuring its security and compliance?
We don’t yet have answers to all of these questions, but we know that we’ll resolve them the same way we always have: through iteration, measurable outcomes, and continued trust and collaboration with each other through this evolution.
Further reading:
- CI for machine learning
- CD for machine learning
- Solving the top 7 challenges of ML model development
- Machine learning CI/CD with Sagemaker