Caching dependencies
On This Page
- Introduction
- How caching works
- Basic example of dependency caching
- Saving cache
- Restoring cache
- Basic example of Yarn package manager caching
- Caching and open source
- Caching libraries
- Writing to the cache in workflows
- Caching race condition example 1
- Caching race condition example 2
- Using caching in monorepos
- Creating and building a concatenated package-lock file
- Managing caches
- Clearing cache
- Cache size
- Viewing network and storage usage
- Using keys and templates
- Further notes on using keys and templates
- Full example of saving and restoring cache
- Source caching
- See also
Caching is one of the most effective ways to make jobs faster on CircleCI. By reusing the data from previous jobs, you also reduce the cost of fetch operations. After an initial job run, subsequent instances of the job run faster, as you are not redoing work.
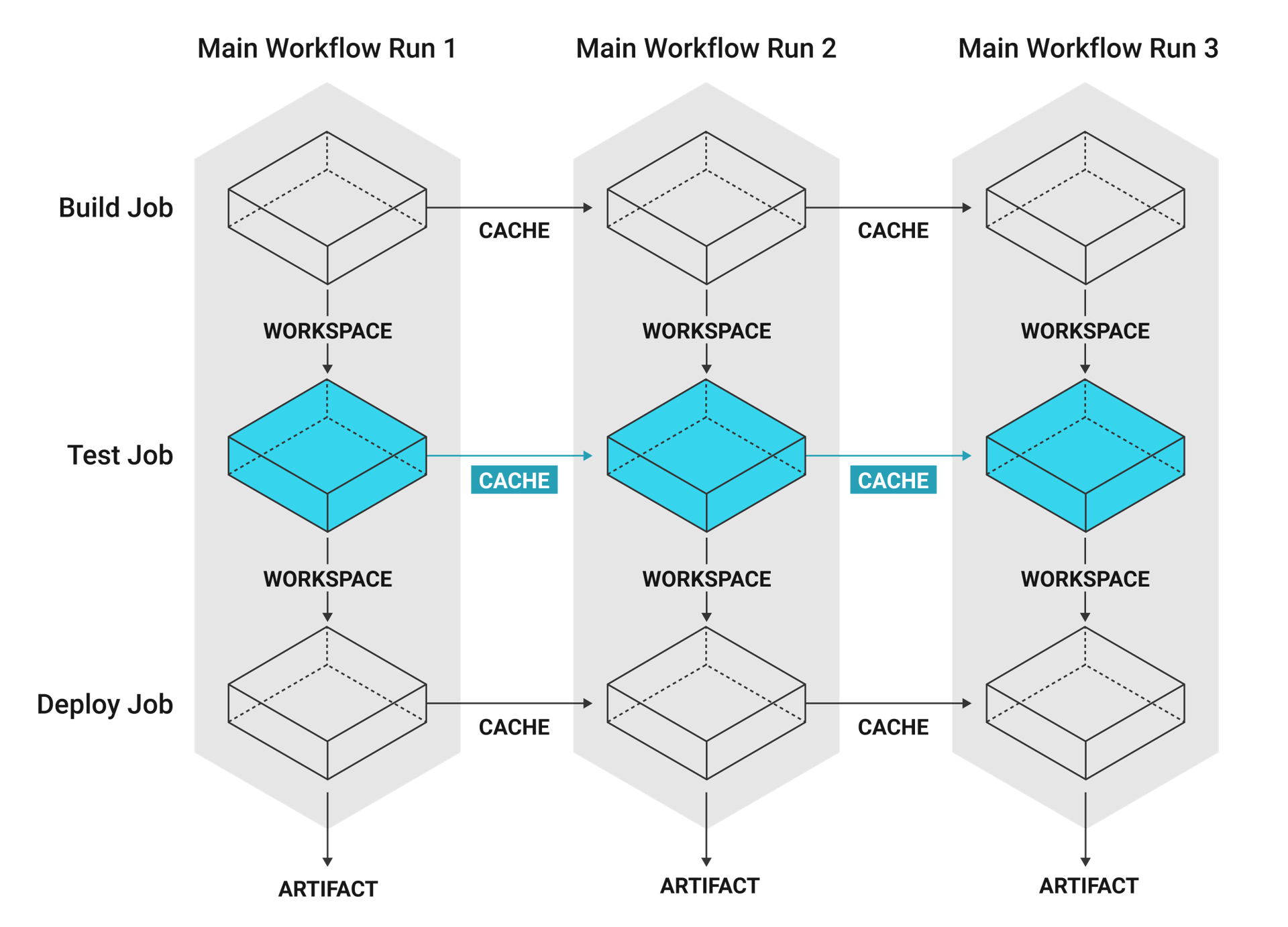
Caching is useful with package dependency managers such as Yarn, Bundler, or Pip. With dependencies restored from a cache, commands like yarn install need only download new or updated dependencies, rather than downloading everything on each build.
| Caching files between different executors, for example, between Docker and machine, Linux, Windows or macOS, or CircleCI image and non-CircleCI image, can result in file permissions and path errors. These errors are often caused by missing users, users with different UIDs, and missing paths. Use extra care when caching files in these cases. |
Introduction
Automatic dependency caching is not available in CircleCI, so it is important to plan and implement your caching strategy to get the best performance. Manual configuration enables advanced strategies and fine-grained control. See the Caching Strategies and Persisting Data pages for tips on caching strategies and management.
This document describes the manual caching options available, the costs and benefits of a chosen strategy, and tips for avoiding problems with caching.
By default, cache storage duration is set to 15 days. This can be customized on the CircleCI web app by navigating to . 15 days is the maximum storage duration you can set.
| The Docker images used for CircleCI jobs are automatically cached on the server infrastructure where possible. |
| Although several examples are included below, caching strategies need to be carefully planned for each individual project. Copying and pasting the code examples will not always be appropriate for your needs. |
For information about caching and reuse of unchanged layers of a Docker image, see the Docker Layer Caching document.
How caching works
A cache stores a hierarchy of files under a key. Use the cache to store data that makes your job faster, but, in the case of a cache miss or zero cache restore, the job still runs successfully. For example, you might cache npm package directories (known as node_modules). The first time your job runs, it downloads all your dependencies, caches them, and (provided your cache is valid) the cache is used to speed up your job the next time it is run.
Caching is about achieving a balance between reliability and getting maximum performance. In general, it is safer to pursue reliability than to risk a corrupted build or to build very quickly using out-of-date dependencies.
Basic example of dependency caching
Saving cache
CircleCI manual dependency caching requires you to be explicit about what you cache and how you cache it. See the save cache section of the Configuring CircleCI document for additional examples.
To save a cache of a file or directory, add the save_cache step to a job in your .circleci/config.yml file:
steps:
- save_cache:
key: my-cache
paths:
- my-file.txt
- my-project/my-dependencies-directoryCircleCI imposes a 900-character limit on the length of a key. Be sure to keep your cache keys under this maximum. The path for directories is relative to the working_directory of your job. You can specify an absolute path if you choose.
Unlike the special step persist_to_workspace, neither save_cache nor restore_cache support globbing for the paths key. |
Restoring cache
CircleCI restores caches in the order of keys listed in the restore_cache step. Each cache key is namespaced to the project and retrieval is prefix-matched. The cache is restored from the first matching key. If there are multiple matches, the most recently generated cache is used.
In the example below, two keys are provided:
steps:
- restore_cache:
keys:
# Find a cache corresponding to this specific package-lock.json checksum
# when this file is changed, this key will fail
- v1-npm-deps-{{ checksum "package-lock.json" }}
# Find the most recently generated cache used from any branch
- v1-npm-deps-Because the second key is less specific than the first, it is more likely there will be differences between the current state and the most recently generated cache. When a dependency tool runs, it would discover outdated dependencies and update them. This is referred to as a partial cache restore.
Each line in the keys: list manages one cache (each line does not correspond to its own cache). The list of keys (v1-npm-deps-{{ checksum "package-lock.json" }} and v1-npm-deps-), in this example, represent a single cache. When it is time to restore the cache, CircleCI first validates the cache based on the first (and most specific) key, and then steps through the other keys looking for any other cache key changes.
The first key concatenates the checksum of package-lock.json file into the string v1-npm-deps-. If this file changed in your commit, CircleCI would see a new cache key.
The next key does not have a dynamic component to it. It is simply a static string: v1-npm-deps-. To invalidate your cache manually, you can bump v1 to v2 in your .circleci/config.yml file. In this case, you would now have a new cache key v2-npm-deps, which triggers the storing of a new cache.
Basic example of Yarn package manager caching
Yarn is an open-source package manager for JavaScript. The packages it installs can be cached, which can speed up builds, but more importantly, can also reduce errors related to network connectivity.
| Yarn 2.x comes with the ability to do Zero Installs. If you are using Zero Installs, you should not need to do any special caching within CircleCI. |
If you are using Yarn 2.x without Zero Installs, you can do something like the following:
steps:
- restore_cache:
name: Restore Yarn Package Cache
keys:
- yarn-packages-{{ checksum "yarn.lock" }}
- run:
name: Install Dependencies
command: yarn install --immutable
- save_cache:
name: Save Yarn Package Cache
key: yarn-packages-{{ checksum "yarn.lock" }}
paths:
- .yarn/cache
- .yarn/unpluggedIf you are using Yarn 1.x, you can do something like the following:
steps:
- restore_cache:
name: Restore Yarn Package Cache
keys:
- yarn-packages-{{ checksum "yarn.lock" }}
- run:
name: Install Dependencies
command: yarn install --frozen-lockfile --cache-folder ~/.cache/yarn
- save_cache:
name: Save Yarn Package Cache
key: yarn-packages-{{ checksum "yarn.lock" }}
paths:
- ~/.cache/yarnCaching and open source
If your project is open source/available to be forked and receive PRs from contributors, make note of the following:
-
PRs from the same fork repository share a cache (this includes, as previously stated, that PRs in the main repository share a cache with main).
-
Two PRs in different fork repositories have different caches.
-
Enabling the sharing of environment variables allows cache sharing between the original repository and all forked builds.
Caching libraries
If a job fetches data at any point, it is likely that you can make use of caching. The most important dependencies to cache during a job are the libraries on which your project depends. For example, cache the libraries that are installed with pip in Python or npm for Node.js. The various language dependency managers, for example npm or pip, each have their own paths where dependencies are installed. See our Language guides and demo projects for the specifics for your stack.
Tools that are not explicitly required for your project are best stored on the Docker image. The Docker image(s) built by the CircleCI team have tools preinstalled that are generic for building projects using the relevant language. For example, the cimg/ruby:3.1.2 image includes useful tools like git, openssh-client, and Gzip.
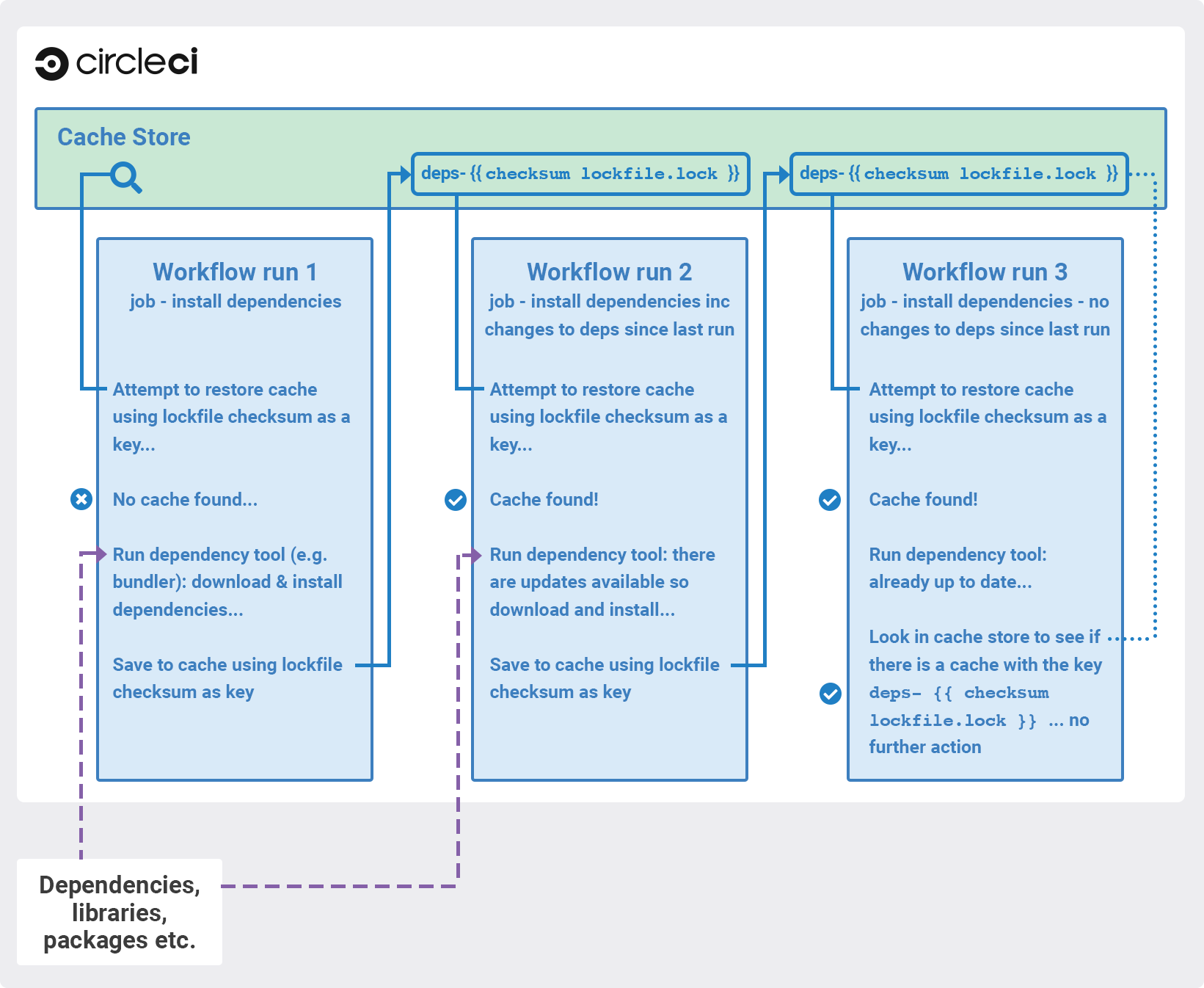
We recommend that you verify that the dependencies installation step succeeds before adding caching steps. Caching a failed dependency step will require you to change the cache key in order to avoid failed builds due to a bad cache.
Example of caching pip dependencies:
version: 2.1
jobs:
build:
docker:
- image: cimg/base:2023.03
steps: # a collection of executable commands making up the 'build' job
- checkout # pulls source code to the working directory
- restore_cache: # **restores saved dependency cache if the Branch key template or requirements.txt files have not changed since the previous run**
key: &deps1-cache deps1-{{ .Branch }}-{{ checksum "requirements.txt" }}
- run: # install and activate virtual environment with pip
command: |
python3 -m venv venv
. venv/bin/activate
pip install -r requirements.txt
- save_cache: # ** special step to save dependency cache **
key: *deps1-cache
paths:
- "venv"Make note of the use of a checksum in the cache key. This is used to calculate when a specific dependency-management file (such as a package.json or requirements.txt in this case) changes, and so the cache will be updated accordingly. In the above example, the restore_cache example uses interpolation to put dynamic values into the cache-key, allowing more control in what exactly constitutes the need to update a cache.
Writing to the cache in workflows
Jobs in one workflow can share caches. This makes it possible to create race conditions in caching across different jobs in a workflow.
Cache is immutable on write. Once a cache is written for a specific key, for example, node-cache-main, it cannot be written to again.
Caching race condition example 1
Consider a workflow of 3 jobs, where Job3 depends on Job1 and Job2: {Job1, Job2} -> Job3. They all read and write to the same cache key.
In a run of the workflow, Job3 may use the cache written by Job1 or Job2. Since caches are immutable, this would be whichever job saved its cache first.
A caching scenario like this is usually undesirable, because the results are not deterministic. Part of the result depends on chance.
You can make this workflow deterministic by changing the job dependencies. For example, make Job1 and Job2 write to different caches, and Job3 loads from only one. Or ensure there can be only one ordering: Job1 -> Job2 -> Job3.
Caching race condition example 2
A more complex caching example could be using a dynamic key, for example, node-cache-{{ checksum "package-lock.json" }} and restoring using a partial key match, for example, node-cache-.
A race condition is still possible, but the details may change. For instance, the downstream job uses the cache from the upstream job that ran last.
Another race condition is possible when sharing caches between jobs. Consider a workflow with no dependency links: Job1 -> Job2. Job2 uses the cache saved from Job1. Job2 could sometimes successfully restore a cache, and sometimes report no cache is found, even when Job1 reports saving it. Job2 could also load a cache from a previous workflow. If this happens, this means Job2 tried to load the cache before Job1 saved it. This can be resolved by creating a workflow dependency: Job1 -> Job2. This forces Job2 to wait until Job1 has finished running.
Using caching in monorepos
The following example is one approach to managing a shared cache based on multiple files in different parts of your monorepo.
Creating and building a concatenated package-lock file
-
Add custom command to config:
commands: create_concatenated_package_lock: description: "Concatenate all package-lock.json files recognized by lerna.js into single file. File is used as checksum source for part of caching key." parameters: filename: type: string steps: - run: name: Combine package-lock.json files to single file command: npx lerna la -a | awk -F packages '{printf "\"packages%s/package-lock.json\" ", $2}' | xargs cat > << parameters.filename >> -
Use custom command in build to generate the concatenated
package-lockfile:steps: - checkout - create_concatenated_package_lock: filename: combined-package-lock.txt ## Use combined-package-lock.text in cache key - restore_cache: keys: - v3-deps-{{ checksum "package-lock.json" }}-{{ checksum "combined-package-lock.txt" }} - v3-deps
Managing caches
Clearing cache
Caches cannot be cleared. If you need to generate a new set of caches you can update the cache key, similar to the previous example. You might wish to do this if you have updated language or build management tool versions.
Updating the cache key on save and restore steps in your .circleci/config.yml file will then generate new sets of caches from that point. Older commits using the previous keys may still generate and save cache, so it is recommended that you rebase after the 'config.yml' changes when possible.
If you create a new cache by incrementing the cache version, the "older" cache is still stored. It is important to be aware that you are creating an additional cache. This method will increase your storage usage. As a general best practice, you should review what is currently being cached and reduce your storage usage as much as possible.
Caches are immutable, so it is helpful to start all your cache keys with a version prefix, for example v1-.... This allows you to regenerate all of your caches just by incrementing the version in this prefix. |
For example, you may want to clear the cache in the following scenarios by incrementing the cache key name:
-
Dependency manager version change, for example, you change npm from 4 to 5.
-
Language version change, for example, you change Ruby 2.3 to 2.4.
-
Dependencies are removed from your project.
Beware when using special or reserved characters in your cache key (for example: :, ?, &, =, /, #), as they may cause issues with your build. Consider using keys within [a-z][A-Z] in your cache key prefix. |
Cache size
You can view the cache size from the CircleCI jobs page within the restore_cache step. There are no limitations on the size of a cache. However, larger caches will generally be saved/restored more slowly than smaller caches as this operation is bounded by network transfer speed.
Viewing network and storage usage
For information on viewing your network and storage usage, and calculating your monthly network and storage overage costs, see the Persisting Data page.
Using keys and templates
A cache key is a user-defined string that corresponds to a data cache. A cache key can be created by interpolating dynamic values. These are called templates. Anything that appears between curly braces in a cache key is a template. Consider the following example:
myapp-{{ checksum "package-lock.json" }}The above example outputs a unique string to represent this key. The example is using a checksum to create a unique string that represents the contents of a package-lock.json file.
The example may output a string similar to the following:
myapp-+KlBebDceJh_zOWQIAJDLEkdkKoeldAldkaKiallQ=If the contents of the package-lock file were to change, the checksum function would return a different, unique string, indicating the need to invalidate the cache.
When choosing suitable templates for your cache key, remember that cache saving is not a free operation. It will take some time to upload the cache to CircleCI storage. To avoid generating a new cache every build, include a key that generates a new cache only if something changes.
The first step is to decide when a cache will be saved or restored by using a key for which some value is an explicit aspect of your project. For example, when a build number increments, when a revision is incremented, or when the hash of a dependency manifest file changes.
The following are examples of caching strategies for different goals:
-
myapp-{{ checksum "package-lock.json" }}- Cache is regenerated every time something is changed inpackage-lock.jsonfile. Different branches of this project generate the same cache key. -
myapp-{{ .Branch }}-{{ checksum "package-lock.json" }}- Cache is regenerated every time something is changed inpackage-lock.jsonfile. Different branches of this project generate separate cache keys. -
myapp-{{ epoch }}- Every build generates separate cache keys.
During step execution, the templates above are replaced by runtime values and use the resultant string as the key. The following table describes the available cache key templates:
| Template | Description |
|---|---|
| A base64 encoded SHA256 hash of a given filename, so that a new cache key is generated if the file changes. This should be a file committed in your repository. Consider using dependency manifests, such as |
| The VCS branch currently being built. |
| The CircleCI job number for this build. |
| The VCS revision currently being built. |
| The environment variable |
| The number of seconds that have elapsed since 00:00:00 Coordinated Universal Time (UTC), also known as POSIX or UNIX epoch. This cache key is a good option if you need to ensure a new cache is always stored for each run. |
| Captures OS and CPU (architecture, family, model) information. Useful when caching compiled binaries that depend on OS and CPU architecture, for example, |
Further notes on using keys and templates
-
A 900 character limit is imposed on each cache key. Be sure your key is shorter than this, otherwise your cache will not save.
-
When defining a unique identifier for the cache, be careful about overusing template keys that are highly specific such as
{{ epoch }}. If you use less specific template keys such as{{ .Branch }}`or `{{ checksum "filename" }}, you increase the chance of the cache being used. -
Cache variables can also accept parameters, if your build makes use of them. For example:
v1-deps-<< parameters.varname >>. -
You do not have to use dynamic templates for your cache key. You can use a static string, and "bump" (change) its name to force a cache invalidation.
Full example of saving and restoring cache
The following example demonstrates how to use restore_cache and save_cache, together with templates and keys in your .circleci/config.yml file.
| This example uses a very specific cache key. Making your caching key more specific gives you greater control over which branch or commit dependencies are saved to a cache. However, it is important to be aware that this can significantly increase your storage usage. For tips on optimizing your caching strategy, see the Caching Strategies page. This example is only a potential solution and might be unsuitable for your specific needs, and increase storage costs. |
version: 2.1
jobs:
build:
docker:
- image: customimage/ruby:2.3-node-phantomjs-0.0.1
environment:
RAILS_ENV: test
RACK_ENV: test
- image: cimg/mysql:5.7
steps:
- checkout
- run: cp config/{database_circleci,database}.yml
# Run bundler
# Load installed gems from cache if possible, bundle install then save cache
# Multiple caches are used to increase the chance of a cache hit
- restore_cache:
keys:
- &gem-cache gem-cache-v1-{{ arch }}-{{ .Branch }}-{{ checksum "Gemfile.lock" }}
- gem-cache-v1-{{ arch }}-{{ .Branch }}
- gem-cache-v1
- run: bundle install --path vendor/bundle
- save_cache:
key: *gem-cache
paths:
- vendor/bundle
- run: bundle exec rubocop
- run: bundle exec rake db:create db:schema:load --trace
- run: bundle exec rake factory_girl:lint
# Precompile assets
# Load assets from cache if possible, precompile assets then save cache
# Multiple caches are used to increase the chance of a cache hit
- restore_cache:
keys:
- &asset-cache asset-cache-v1-{{ arch }}-{{ .Branch }}-{{ .Environment.CIRCLE_SHA1 }}
- asset-cache-v1-{{ arch }}-{{ .Branch }}
- asset-cache-v1
- run: bundle exec rake assets:precompile
- save_cache:
key: *asset-cache
paths:
- public/assets
- tmp/cache/assets/sprockets
- run: bundle exec rspec
- run: bundle exec cucumber| Using Docker? Authenticating Docker pulls from image registries is recommended when using the Docker execution environment. Authenticated pulls allow access to private Docker images, and may also grant higher rate limits, depending on your registry provider. For further information see Using Docker authenticated pulls. |
Source caching
It is possible and often beneficial to cache your git repository to save time in your checkout step, especially for larger projects. Here is an example of source caching:
steps:
- restore_cache:
keys:
- &source-cache source-v1-{{ .Branch }}-{{ .Revision }}
- source-v1-{{ .Branch }}-
- source-v1-
- checkout
- save_cache:
key: *source-cache
paths:
- ".git"In this example, restore_cache looks for a cache hit in the following order:
-
From the current git revision
-
From the current branch
-
For any cache hit, regardless of branch or revision.
When CircleCI encounters a list of keys, the cache is restored from the first match. If there are multiple matches, the most recently generated cache is used.
If your source code changes frequently, we recommend using fewer, more specific keys. This produces a more granular source cache that updates more often as the current branch and git revision change.
Even with the narrowest restore_cache option (source-v1-{{ .Branch }}-{{ .Revision }}), source caching can be greatly beneficial, for example:
-
Running repeated builds against the same git revision (for example, with API-triggered builds)
-
When using workflows, where you might otherwise need to
checkoutthe same repository once per workflow job.
However, it is worth comparing build times with and without source caching. git clone is often faster than restore_cache.
The built-in checkout command disables git’s automatic garbage collection. You might choose to manually run git gc in a run step prior to running save_cache to reduce the size of the saved cache. |