Testing LLM-enabled applications through evaluations
This page describes methods for testing applications powered by large language models (LLMs) through evaluations, including automating evaluations with CircleCI.
Evaluations overview
Evaluations, also known as evals, are a methodology for assessing the quality of AI software.
Evaluations provide insights into the performance and efficiency of applications based on LLMs, and allow teams to quantify how well their AI implementation works, measure improvements, and catch regressions.
The term evaluation initially referred to a way to rate and compare AI models. Evaluation has since expanded to include application-level testing, including Retrieval Augmented Generation (RAG), function calling, and agent-based applications.
The evaluation process involves using a dataset of inputs to an LLM or application code, and a method to determine if the returned response matches the expected response. Following is a list of evaluation methodologies with descriptions of each:
- LLM-assisted evaluations
-
Language models are used as automated judges to assess outputs from other models.
- Human evaluations
-
Human raters directly assess model outputs through techniques like preference comparisons, Likert scales, or rubric-based scoring.
- Intrinsic evaluations
-
Assess a model’s inherent capabilities and linguistic properties without relying on specific applications.
- Extrinsic evaluations
-
Measure a model’s performance on practical downstream tasks or benchmarks to determine real-world effectiveness.
- Bias and fairness checks
-
Systematically probe for and quantify a model’s tendency to produce unfair, stereotyped, or discriminatory content across different demographic groups.
- Readability evaluations
-
Assess how accessible and comprehensible a model’s outputs are for target audiences using metrics like Flesch-Kincaid or analysis of linguistic complexity.
Evaluations can cover many aspects of a model performance, including:
-
Ability to comprehend specific jargon
-
Make accurate predictions
-
Avoid hallucinations and generate relevant content
-
Respond in a fair and unbiased way, and within a specific style
-
Avoid certain expressions
Some important differences between evaluations and standard software tests to consider include the following:
-
LLMs are predominantly non-deterministic, leading to flaky evaluations, more so than typical deterministic software tests.
-
Evaluation results are subjective. Small regressions in a metric might not necessarily be a cause for concern, unlike failing tests in standard software testing.
-
Evaluation results are manually reviewed to determine whether AI application performance meets expectations since the output metric values can fluctuate.
Using an open source library or third-party tools can simplify defining evaluations, tracking progress, and reviewing evaluation results.
Automate evaluations with CircleCI
Evaluations can be automated in CircleCI pipelines. CircleCI enables you to automate decisions regarding the following:
-
Acceptance of proposed AI application changes.
-
Deployment and release of your AI application.
With CircleCI, you can define, automate, run evaluations and evaluation testing using your preferred evaluation framework. Through declaring the necessary commands in your pipeline configuration you can ensure evaluations are run and evaluation results are tested within your CircleCI pipeline.
You can automate your entire process of running evaluations, reviewing evaluation results and determining whether results meet expectations, removing manual work involved with triggering evaluations and reviewing evaluation results.
The CircleCI evals orb
CircleCI provides an evals orb, which offers the following capabilities:
-
Simplifies the definition and execution of evaluation jobs using custom scripts and popular third-party tools.
-
Generates reports of evaluation results.
-
Tests evaluation results to determine if they meet specified conditions.
Run evaluations in CircleCI
With the CircleCI evals orb, evaluations:
-
Will run as part of your CircleCI pipeline.
-
Job step details can include direct links to your evaluation results stored on your 3rd party evaluations provider. When you need to further review the evaluation results in detail, this link enables you to navigate to and view your evaluation results.
-
Your evaluation results can be saved to a
.jsonfile, for evaluation testing.

Test evaluation results in CircleCI
Evaluation testing enables you to determine if your evaluation results meet specified conditions. CircleCI evaluation testing uses a suite of test cases. Each test case represents a scenario with an assertion to check if a specified condition is true or false. If any test case fails, the evaluation test fails.
Assertions are expressed using the Common Expression Language (CEL). For more information, see the specification. All values from the results .json file are available as global variables. Try out CEL here.

Assuming the evaluation results are in a .json file, as follows:
{
"correctness": 0.99,
"toxicity": 0.2,
"labels": [
"CORRECT",
"ACCURATE",
"NOT HARMFUL"
]
}You can configure test case assertions, like this:
-
Thresholds: Check whether 1 or more results fall within a range.
{ "correctness": "correctness > 0.9" "toxicity": "toxicity < 0.01" } -
Equality: Check whether results provide an expected answer.
{ "labels": "labels[0] == \"CORRECT\"" }
Test cases are composed of a name and an assertion. In the first example above, the name is correctness and the assertion is that correctness will be above 0.9. When configuring test cases, we suggest assigning a name based on the test scenario. The examples above use names based on input metrics: correctness , toxicity and labels.
Evaluation testing results determine if a job should stop or continue, as follows:
-
The evaluation test fails: This indicates a proposed change resulted in a degradation of model performance. The job stops running, and the pipeline fails.
-
The evaluation test passes: This indicates that model performance has met set criteria, the job continues to run.
View evaluation test results
Evaluation testing determines if your evaluation results meet specified conditions. Evaluation testing results are presented in the CircleCI web app in two locations:
-
In the step details

-
In the tests tab. Additionally, when a test case has failed, its details are displayed.

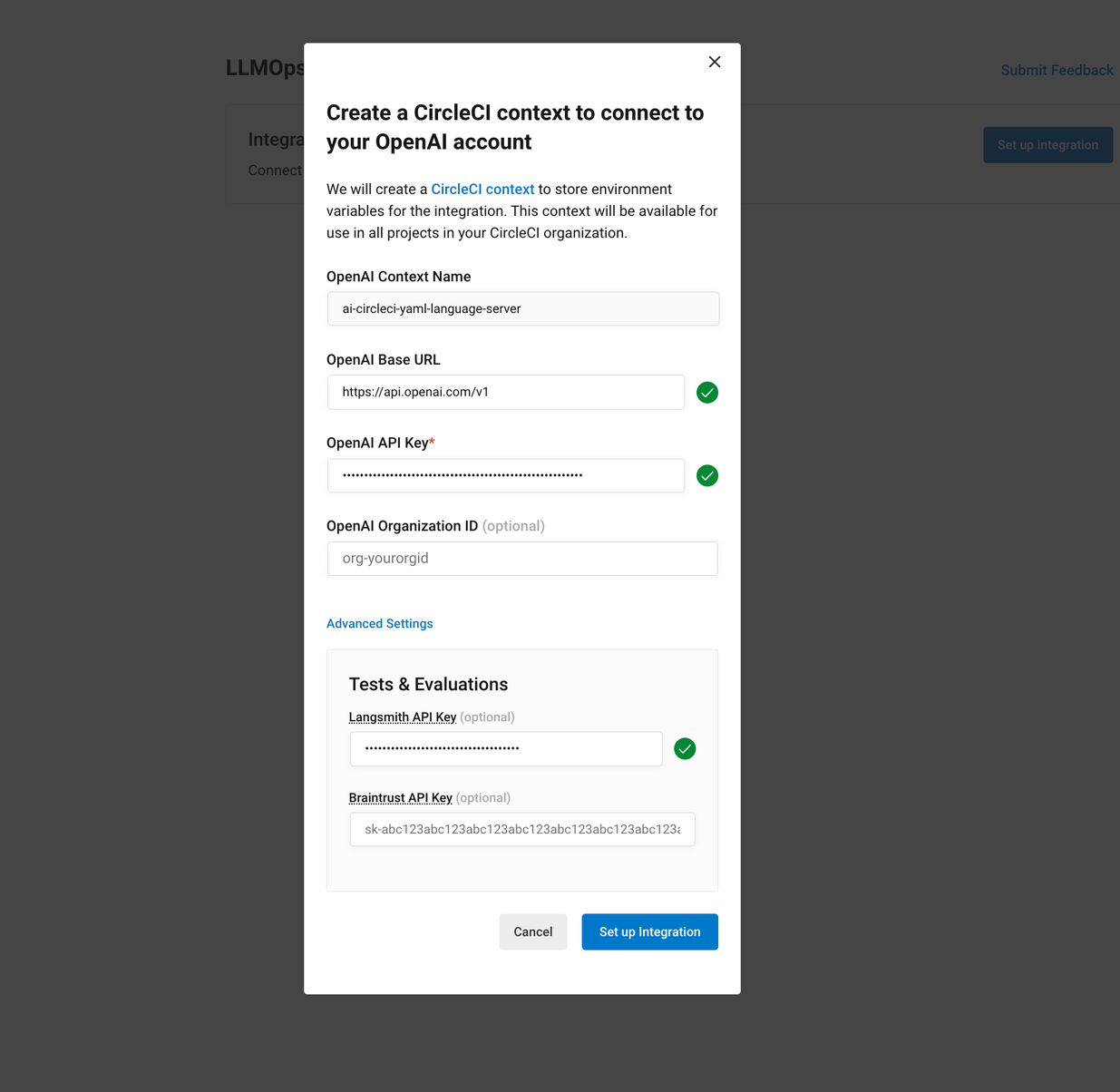
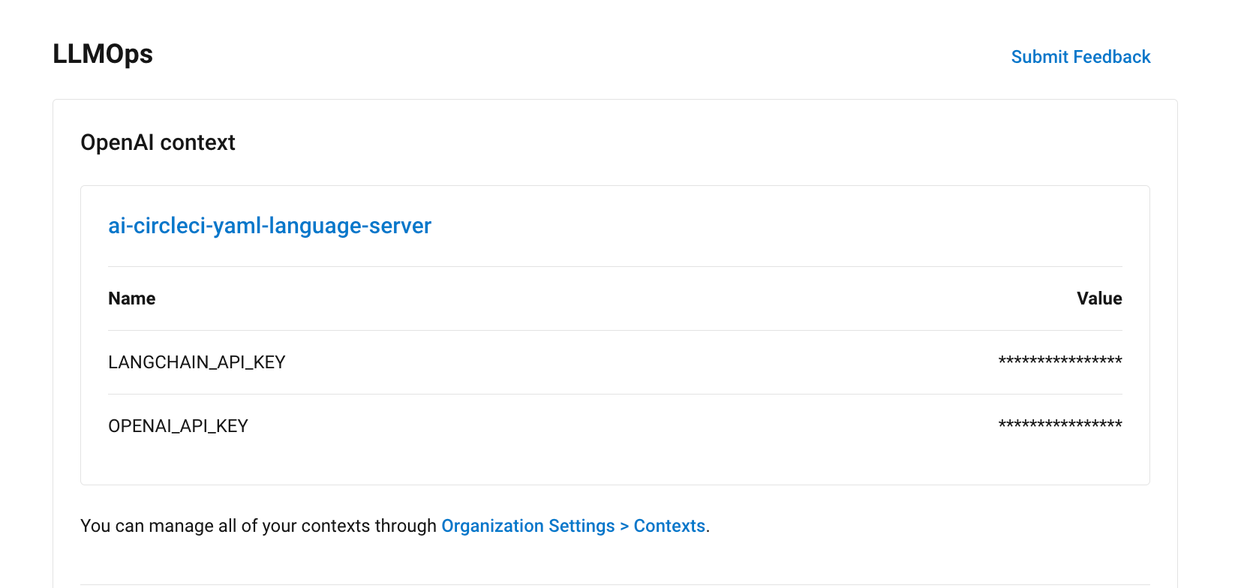
Store credentials for your evaluations
Store your credentials for LLM providers and LLMOps tools in CircleCI. Storing credentials in this way allows you to access them directly when configuring your pipeline.
To store your LLM provider credentials, follow these steps:
-
Navigate to
-
Select Set Up next to your chosen provider, and follow the in-app instructions.
-
When connecting an OpenAI account, you can also save the credentials for your evaluation platform, such as Braintrust and LangSmith. These credentials can then be used when setting up a pipeline that uses the CircleCI evals orb.
-
Next steps
-
Follow our how to guide to automate LLM evaluation testing with the CircleCI evals orb.