Polyglot persistence vs multi-model databases for microservices

Senior Technical Content Marketing Manager

Microservice architecture is an application system design pattern in which an entire business application is composed of individual functional scoped services, which can scale on demand. Each team focuses on an individual service and builds it according to their skillset or language of choice.
In addition to flexibility, this pattern provides:
- Less risk in introducing a change because of the loosely coupled service patterns
- Independent scaling abilities of each service
- Containerized deployment options
These features have made microservices architecture a popular choice for enterprises.
Before the microservices era, enterprises built their applications using monolithic design patterns, which ran on an on-site, high-capacity server (data center). Whether your application uses a monolithic or microservices design pattern, you must have a storage solution to persist the data it manages.
What sort of data storage solution should your team select to serve your microservice architectures? In this article, we will look at two popular approaches, polyglot persistence and multi-model databases, as well as criteria you can use to determine which solution is best suited for your application.
Database management challenges for microservices
Monolithic apps typically have a single database, while microservices have a more decentralized model. This means that in most real-world deployments, each microservice has its own database.
Although each team can choose its programming language and database, such an approach comes with challenges. One critical challenge is implementing queries and atomic, consistent, isolated, and durable (ACID) transactions for requests spanning multiple services.
Achieving ACID transactions or implementing a query logic is simple in a monolith application. To query microservices, you need to implement query logic with extra care and a well-designed approach.
In the software industry, patterns exist to address such database management challenges for microservices. Next is a brief overview of such patterns.
Database-per-service
Microservices following a database-per-service pattern have individual databases for each service. This pattern promotes loose coupling, at both the application processing and computational level, and also at the storage level. If a service depends on another service’s data, it must make an API call.
Saga pattern
With the Saga pattern, microservice applications have a way to communicate with multiple services in a transaction-like way. In this case, a single business transaction executes as a sequence of transactions in each dependent service. If transactions in all services are successful, the entire transaction is a success. In case of a transaction failure in any microservice, an equivalent reverse transaction rolls back the failed transaction.
API composition pattern
Consider a business application based on multiple microservices. Assume that a user is interested in a key performance indicator (KPI) that depends on data from three different microservices. Instead of expecting the user to make an API request for each service, you can deploy an API composition pattern to ease this process.
With an API composition pattern, you design a separate service to expose an API that takes care of abstracting the technicalities of retrieving data from multiple services. This service joins the retrieved data in memory and returns the KPI details to the user.
Event sourcing pattern
The event sourcing pattern advocates for and paves a way to store each incoming event in a microservice application. You can then use these persisted events for auditing, and later for events replay, in failure handling scenarios, for example.
Shared database anti-pattern
In this anti-pattern, multiple services share a single database. It composes loose coupling characteristics and makes the microservices prone to a single point of failure. Note that the shared database approach is an anti-pattern, in contrast to the previously-described microservices design patterns.
What is polyglot persistence?
In most cases, a technical team prefers a database-per-service pattern to benefit from its loosely coupled services. With the recent advancement in database technologies, there are multiple flavors of data storage solutions available. Each performs the best for its targeted use cases.
For example, if your microservice needs the flexibility of a schemaless, document-like storage solution, you can choose a document store like MongoDB. If your microservice needs to establish a connection between millions or billions of users or entities, you can use a Graph store like Neo4j.
The point is that you now have a wide variety of database options to meet your business needs. These options perform well for the use case of your microservice — which is exactly why you need polyglot persistence.
Polyglot persistence involves using specialized database solutions when developing microservices, so each microservice can use a different type of database than the one used by another microservice.
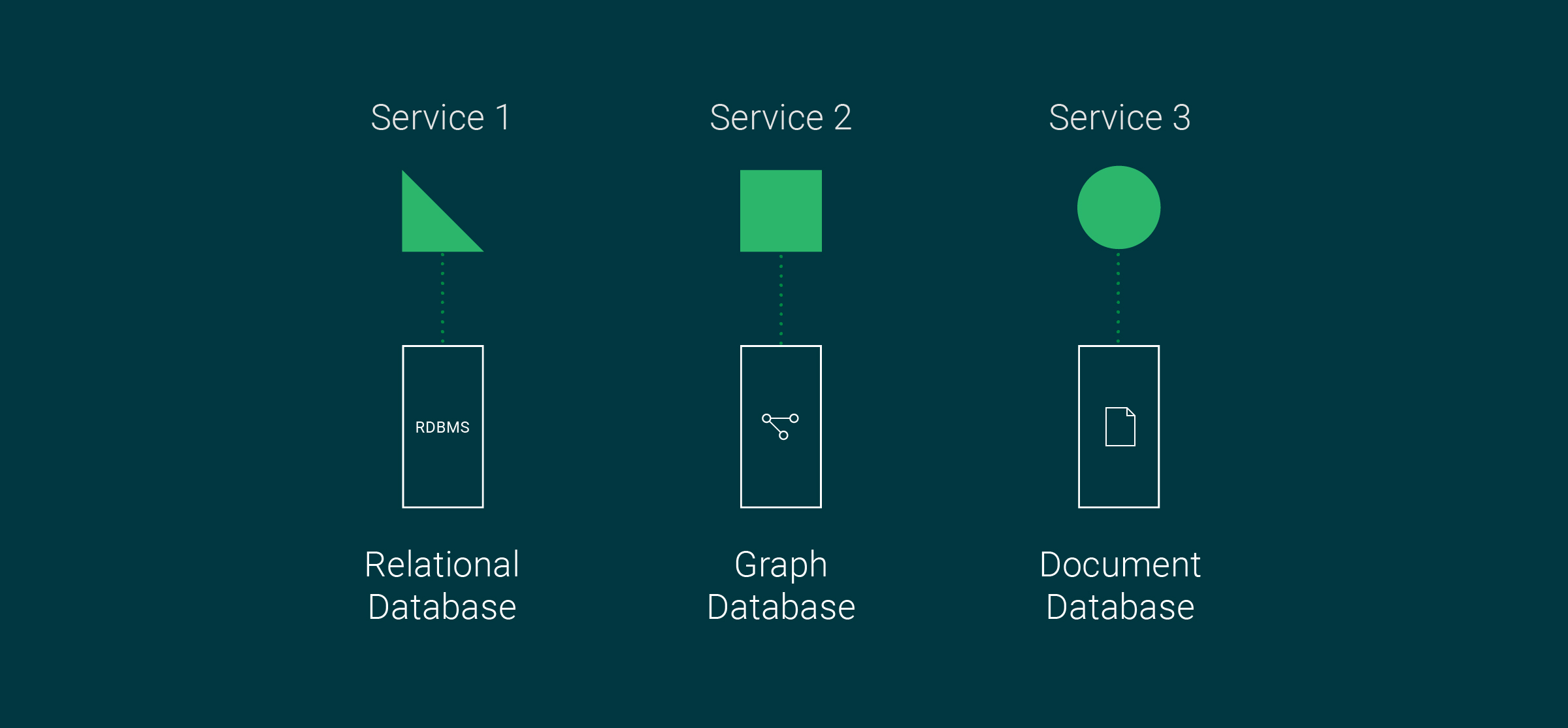
Here is a list of database technology categories and their most common use cases:
- RDBMS: When a strict schema and ACID transactions are necessary, use relational (RDBMS) databases.
- Graph databases: When a quick traversal of links and relationships is essential, use graph databases.
- Document-based databases: When a flexible schema or schemaless structure is needed, and you must handle high data volumes, use a document store.
- Key-value databases: When fast reads and writes are essential, use key-value stores.
With the polyglot persistence model, each service deals with its database storage solution and databases to meet your functional and non-functional application goals.
What is a multi-model database?
A multi-model database is a single database engine storing multiple data models and types. Using one back-end engine, you can design schema models in a multi-model database to store relational, non-relational, document, key-value, and graph data.
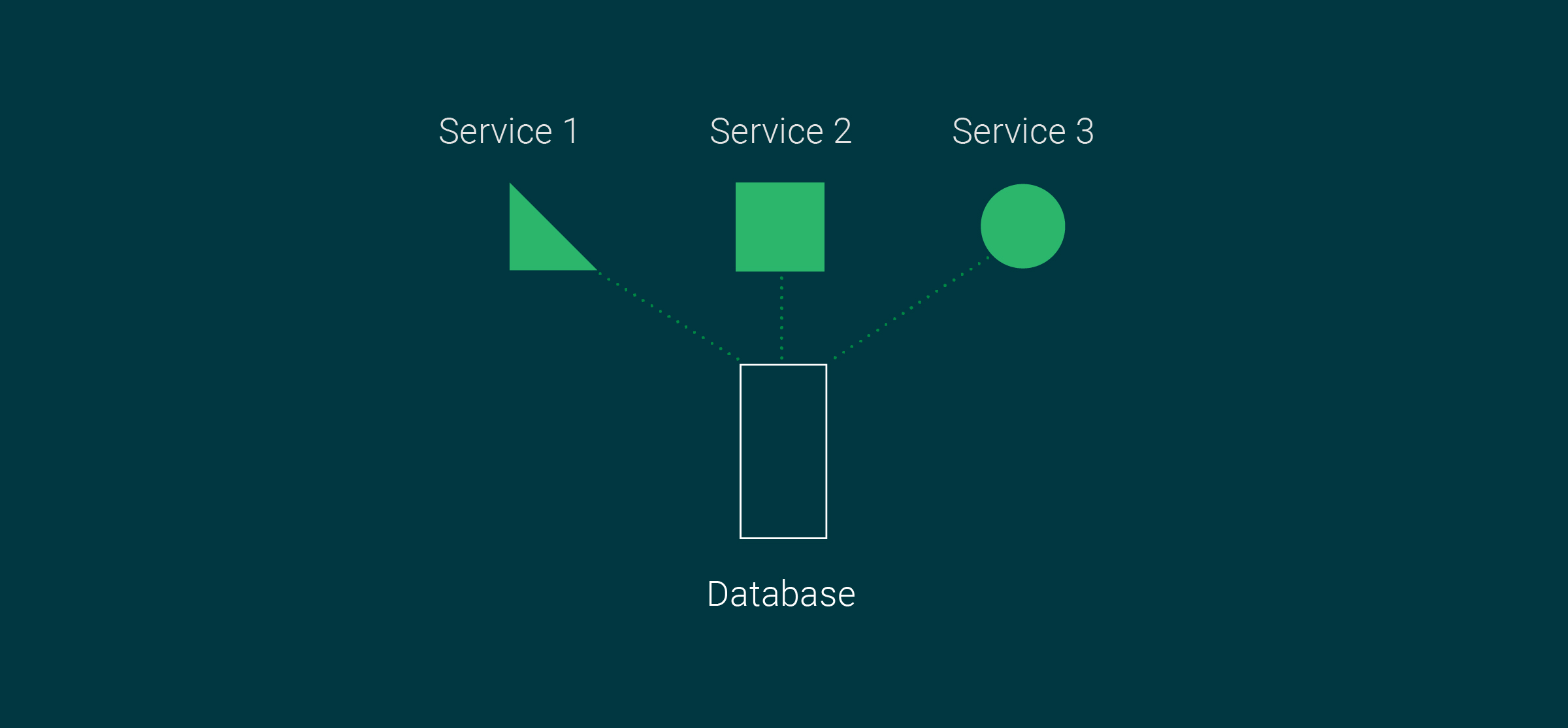
It is important to note that not all multi-model database engines support every format of data models in the market. Some may support three data models (relational, document, and graph), while others may support four schema models (relational, document, graph, and key-value store).
So, how does a multi-model database engine work to keep various schema models or data categories in its one engine? The answer lies in the semantic model. Usually, a multi-model database makes its data definition language and query language simple for its users by abstracting the complexity of defining models and retrieving data from multiple data models.
Key reasons an organization might use a multi-model database engine as their backend choice:
- Only one database to manage instead of multiple, but it is still possible to exploit the advantages of defining multiple models and storing different data types.
- One semantic model to learn and use for interacting with the data stored in a multi-model database.
Polyglot persistence vs multi-model databases: Which is best for microservices?
The benefits of polyglot persistence for microservices are:
- Services remain loosely coupled.
- Based on the specialized data store requirement of the service, you can choose the best, most reliable, and scalable data store with a relatively long history of use and a proven record of success in the market.
- If multiple vendors or open source database engines are available to serve the chosen data model, you can make the database choice based on your team’s skillset or preference.
The benefits of multi-model persistence for microservices are:
- You have a single multi-model database engine to manage instead of multiple kinds of databases.
- You only need to learn one semantic model for interacting with the data stored in the database.
- Managing one database engine type instead of several makes administration much easier.
- There is only a single vendor license to manage.
Now that you have seen the benefits of polyglot and multi-model persistence, which solution excels over the other for a given use case? The answer can vary.
If your microservices use case depends on three different schema models, for example relational, document, and graph, check for the existence of a multi-model database engine that supports all three in a single database engine. If it does, then you should use a multi-model database for microservices.
However, if your use case requires five different schema models, like relational, document, columnar, key-value, and graph, you may not be able to find a multi-model database engine that supports them all. In that case, use polyglot persistence or a combination of polyglot and multi-model persistence.
Next steps
Many application development teams are moving towards microservices-based architectures. The importance of data stores remains high even for a microservice application. Different patterns have evolved in the market to address database management challenges for microservices.
Businesses have widely adopted the database-per-service design for its loosely coupled benefits and the other advantages it offers. When you use a database-per-service pattern for implementing microservices, you can choose between polyglot or multi-model persistence. The choice depends on the use case, your enterprise size, and your working model.
If you have a large enterprise and have a dedicated database team with skilled professionals to take care of multiple data stores, then you should use polyglot persistence. Polyglot persistence lets you choose a database engine for each data model segment that has a proven history in that category.
In the case of multi-model database space, almost all vendors are recent and do not have a long record in the production environment. So, if you think a multi-model persistence approach is risky, choose polyglot persistence.
If you are a start-up organization with a relatively small team, however, you can use a multi-model database to meet your microservices and heterogeneous data store requirements. It will improve productivity and reduce both manual and hardware resource costs.
Now that you have enough information about this space, you are prepared to choose the persistence model that can best suit your microservice application. To continue optimizing your microservices development processes, consider adopting continuous integration and continuous delivery to help you automatically test changes to your microservices and deploy your application using popular tools like Kubernetes. You can get started by signing up for a free CircleCI account today.

